-
2014-01-20
Active-active Alfresco cluster with MySQL Galera and GlusterFS
January 20, 2014
By Severalnines
Alfresco is a popular collaboration tool available on the open-source market. It is Java based, and has a…
-
2014-01-16
Testing GlusterFS during “Glusterfest”
The GlusterFS community is having a “test day”. Puppet-Gluster+Vagrant is a great tool to help with this, and it has now been patched to support alpha, beta, qa, and rc releases! Because it was built so well (*cough*, shameless plug), … Continue reading →

-
2014-01-15
The 4K Desktop on Fedora
Like a lot of folks, I caught the “4K is for Programmers” post off Hacker News a few days ago (it’s here, but the link seems to be borked at the moment) and got to thinking about more desktop space. Much more. My current setup, when not traveling, involves a 27″ 2560×1440 display – usually […]
-
2014-01-15
Gluster and oVirt Test Days Coming Up
If you’re a fan of scale-out storage, datacenter virtualization, or (like me) a mixture of the two, you’ll want to mark your calendar for this pair of upcoming test days for the Gluster and oVirt projects.
This weekend, from Friday the 17th at midnight UTC to Monday the 20th at midnight UTC, the Gluster project is having a test weekend (aka Glusterfest) for its 3.5 release. There’s a breakdown of all the features slated for 3.5 on the release’s planning page.
For this Glusterfest iteration, the project hopes to smooth the process of multi-node testing with the availability of James Shubin’s Puppet-Gluster module. James recently wrote the how-to post, Automatically deploying GlusterFS with Puppet-Gluster + Vagrant, which ought to come in handy this weekend.
After giving James’ post a run-through myself, I’m interested in trying it out with this Vagrant oVirt/RHEV Provider I found on github.
Speaking of oVirt, the project has its own test day coming up on January 23rd, this one for the project’s 3.4 release.
The oVirt 3.4 feature I’m most excited about is the Self Hosted Engine option, in which one or more oVirt compute nodes can host the oVirt management engine. This feature promises to eliminate the engine as a single point of failure, as well as free up the separate machine that’s typically used to host the engine.
If you’re raring to jump on the 3.4 code right away, alpha packages are now available. Check out these release notes for more information about how to get rolling.
For more information on this weekend’s Glusterfest, check out the Gluster project wiki. To find out more about next week’s oVirt 3.4 Test Day, check out the oVirt project wiki.
-
2014-01-12
Adding new virtual disks to running virt images.
I always finding my self clicking UI’s and modifying command line incantations to create VMs with new virtual block devices. This is probably pretty common to anyone who is using VMs to mimic a real world environment where there is a dedicated de…
-
2014-01-09
Configuring OpenStack Havana Cinder, Nova and Glance to run on GlusterFS
Configuring Glace, Cinder and Nova for OpenStack Havana to run on GlusterFS is actually quite simple; assuming that you’ve already got GlusterFS up and running.
So lets first look at my Gluster configuration. As you can see below, I have a Gluster volume defined for Cinder, Glance and Nova.… Read the rest
The post Configuring OpenStack Havana Cinder, Nova and Glance to run on GlusterFS appeared first on vmware admins.
-
2014-01-08
Automatically deploying GlusterFS with Puppet-Gluster + Vagrant!
Puppet-Gluster was always about automating the deployment of GlusterFS. Getting your own Puppet server and the associated infrastructure running was never included “out of the box“. Today, it is! (This is big news!) I’ve used Vagrant to automatically build these … Continue reading →

-
2014-01-02
Ajax + Maven + S3 = A lightweight maven repository browser that never goes down.
Heavyweight interfaces sometimes occlude the simple, platform neutral, static directory structure that made maven famous to begin with. If your server goes down, your jars are unavailable. S3 solves this problem by providing serverless, htt…
-
2014-01-01
Vagrant clustered SSH and ‘screen’
Some fun updates for vagrant hackers… I wanted to use the venerable clustered SSH (cssh) and screen with vagrant. I decided to expand on my vsftp script. First read: Vagrant on Fedora with libvirt and Vagrant vsftp and other tricks … Continue reading →

-
2013-12-21
Vagrant vsftp and other tricks
As I previously wrote, I’ve been busy with Vagrant on Fedora with libvirt, and have even been submitting, patches and issues! (This “closed” issue needs solving!) Here are some of the tricks that I’ve used while hacking away. Default provider: … Continue reading →

-
2013-12-19
Installing GlusterFS on RHEL 6.4 for OpenStack Havana (RDO)
The OpenCompute systems are the the ideal hardware platform for distributed filesystems. Period. Why? Cheap servers with 10GB NIC’s and a boatload of locally attached cheap storage!
In preparation for deploying RedHat RDO on RHEL, the distributed filesystem I chose was GlusterFS.… Read the rest
The post Installing GlusterFS on RHEL 6.4 for OpenStack Havana (RDO) appeared first on vmware admins.
-
2013-12-19
Git: Submodules are to hot. Subtrees are to cold. Just use fetch ?

Submodules and subtrees are too complicated… Sometimes you can just use git fetch to share code between repos. Disclaimer: This post is EXTREMELY simple. It is for begginers in git that want to create composite projects but don’t really want to dive into the labarynthine realm of submodules / subtrees.
This post outlines an easy and simple way to share code from “project A” into “project B”, using “git fetch”, and leveraging the fact that git supports multiple remotes. In the end, you’r “project B” will have two remotes: its own, and that of “project A”. It will replicate the history of project A also (which is not necessarily ideal, but, thats the approach that we will go with – if you want REAL dependency management : use a real dependency manager / build tool like maven/rpm/etc).
This workflow for maintaining a composite git project:
1) Doesnt require custom subtree stuff
2) Won’t trip you up with new semantics in your git workflow
3) Is totally transparent : All history will be in your commit log and no where else.Why bother posting a manual methodology for managing git based dependent projects? Because I’m not sure there is a good git based tool for this yet.
A breif aside on the alternatives:Submodules
“if you forget to update your submodule to the new version, it’s then quite easy to commit the old submodule version in your next parent repository commit – thus effectively reverting the submodule bump by the other developer.” – from http://codingkilledthecat.wordpress.com/2012/04/28/why-your-company-shouldnt-use-git-submodules/.
Thus : submodules are really complicated. At first glance, thats not a big deal, but over time, you can lose alot of code and lose commits when submodules arent managed properly, because of the fact that they descend into a detached state.
Subtrees
Subtrees aren’t part of the standard “git” that everyone has. Its kind of strange to force people to have to set up a “special” git component just to use subtrees. After all, subtrees aren’t really perfect either !
Since they duplicate the commits and code into a your super repository, they are actually quite similar to a fetch (correct me if im wrong here – im not subtree expert, but they really seem like little more than an source embedding tool with a little extra syntactic sugar).
A simpler way to share code between projects: git fetch!
I know this is dead simple. So simple maybe it doesnt even deserve a blog post. But… I bet somebody will find it useful. After all, there are alot of folks using git out there and not all of them want to spend all day figuring out peripheral git utilities just to pull a few files into their superproject.
So here’s a dead simple example of how to feed code from one project into another using git fetch:Lets say I have two repos: A community one and a private one.
I can easily pull from my community into my private by the following workflow:
- Create two repos (one called “community”, the other called “private”).
- Go into your community repo: git@github.com:my_name/my_community_repo.git
- touch community_file
- git add community_file ;
- git commit -m “first communal commit”
- git push origin master # <– payload = 1 commit.
- Go into your private repo:
- git remote add community git@github.com:my_name/my_community_repo.git
- git fetch community
- git merge remotes/community/master
- NOTE: If you DONT want to put the commits in with the merge, you can run
"git merge remotes/community/master --no-commit --no-ff" - git push origin master # <– payload = 2 commits.
You can see how it pans out here:
https://github.com/jayunit100/mock_community <– has commits from community repo
And
https://github.com/jayunit100/mock_private <– has commits from community repo + its own commit.
^^ If that looks like what you wanted, then you can (maybe) forget about using the git sub* tools and just read the man page for “git fetch”.
The downside
Okay so , what happens when your code diverges ? You have to manually pull in the latest from your upstream repo and commit it. Well… thats not so bad. At least you know what you have to do and have the tools to do it in your head and in any old git distro.
Moral of the story
Well, i guess if you want REAL dependency management : you can use a dependency manager like maven, gradle, pip, yum, or whatever. From what I can tell, git wasn’t built to manage dependencies. Until then – just fetch from different repositories and push those commits into your own repo 🙂
Remember that git really does a great job supporting multiple remotes! So use them to your advantage 🙂 -
2013-12-11
A few isoteric Jenkins tricks I had to do last week
Jenkins seems to do EVERYTHING for you , sometimes. Well.. here’s some stuff it doesnt do:Update !I’ve posted a video on how we glued together our CI according to the diagram above for glusterfs-hadoop. In particular, it goes over:Setting u…
-
2013-12-11
Gluster and (not) restarting brick processes upon updates
Gluster users have different opinions on when the Gluster daemons should be restarted. This seems to be a very common discussion for a lot daemons, and pops up on the Fedora Developers mailinglist regularly.An explanation on how and when Gluster starts…
-
2013-12-11
Gluster and (not) restarting brick processes upon updates
Gluster users have different opinions on when the Gluster daemons should be restarted. This seems to be a very common discussion for a lot daemons, and pops up on the Fedora Developers mailinglist regularly.An explanation on how and when Gluster starts…
-
2013-12-09
Vagrant on Fedora with libvirt
Apparently lots of people are using Vagrant these days, so I figured I’d try it out. I wanted to get it working on Fedora, and without Virtualbox. This is an intro article on Vagrant, and what I’ve done. I did … Continue reading →

-
2013-12-01
Using Gluster as Primary Storage in CoudStack
CloudStack could use a Gluster environment for different kind of storage types: Primary Storage: mount over the GlusterFS native client (FUSE)This post shows how it is working and refers to the patches that make this possible.Volumes for virtual machin…
-
2013-12-01
Using Gluster as Primary Storage in CoudStack
CloudStack could use a Gluster environment for different kind of storage types: Primary Storage: mount over the GlusterFS native client (FUSE)This post shows how it is working and refers to the patches that make this possible.Volumes for virtual machin…
-
2013-11-27
Effective GlusterFs monitoring using hooks
Let us imagine we have a GlusterFs monitoring system which displays list of volumes and its state, to show the realtime status, monitoring app need to query the GlusterFs in regular interval to check volume status, new volumes etc. Assume if the polling interval is 5 seconds then monitoring app has to run
gluster volume infocommand ~17000 times a day!How about maintaining a state file in each node? which gets updated after every new GlusterFs event(create, delete, start, stop etc).
In this blog post I am trying to explain the possibility of creating state file and using it.
As of today GlusterFs provides following hooks, which we can use to update our state file.
create delete start stop add-brick remove-brick set
How to use hooks
GlusterFs hooks present in
/var/lib/glusterd/hooks/1directory. Following example shows sending message to all users usingwallcommand when any new GlusterFs volume is created.Create a shell script
/var/lib/glusterd/hooks/1/create/post/SNotify.bashand make it executable. Whenever a volume is created GlusterFs executes all the executable scripts present in respective hook directory(Glusterfs executes only the scripts which filename starting with ‘S’)#!/bin/bash VOL= ARGS=$(getopt -l "volname:" -name "" $@) eval set -- "$ARGS" while true; do case $1 in --volname) shift VOL=$1 ;; *) shift break ;; esac shift done wall "Gluster Volume Created: $VOL";
Experimental project – GlusterWeb
This experimental project maintains a sqlite database
/var/lib/glusterd/nodestate/glusternodestate.dbwhich gets updated after any GlusterFs event. For example if a GlusterFs volume is created then it updates volumes table and also bricks table.This project depends on glusterfs-tools so install both projects.
git clone https://github.com/aravindavk/glusterfs-tools.git cd glusterfs-tools sudo python setup.py install git clone https://github.com/aravindavk/glusterfs-web.git cd glusterfs-web sudo python setup.py install
By running setup, this tool will install all the hooks which are required for monitoring. (cleanup is for removing all the hooks)
sudo glusternodestate setup
All set! now run
glusterwebto start webapp.sudo glusterweb
Web application starts running in
http://localhost:8080you can change the port using--portor-poption.sudo glusterweb -p 9000
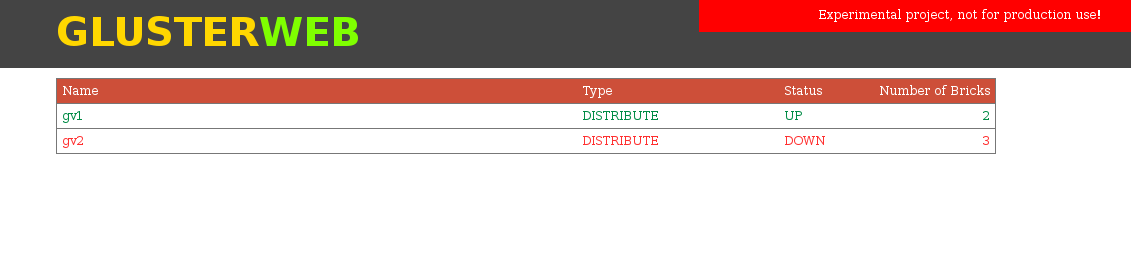
Initial version of web interface.
Future plans
Authentication: Option to provide username and password or access key while running glusterweb, For example
sudo glusterweb --username aravindavk --password somesecret # or sudo glusterweb --key secretonlyiknowMore gluster hooks support: we need more GlusterFs hooks for better monitoring(refer Problems below)
More GlusterFs features support: As a experiment UI only lists volumes, we need improved UI and support for different gluster features.
Actions support: Support for volume creation, adding/removing bricks etc.
REST api and SDK: Providing REST api for gluster operations.
Many more: Not yet planned 🙂
Problems
State file consistency: If glusterd goes down in the node then the database will have wrong details about node’s state. One workaround is to reset the database if glusterd is down using a cron job, when glusterd comes up, database will not gets updated and the database will have previous updated details. To prevent this we need a glusterfs hook for glusterd-start.
More hooks: As of today we don’t have hooks for volume down/up, brick down/up and other events. We need following hooks for effective monitoring glusterfs.(Add more if anything missing in the list)
glusterd-start peer probe peer detach volume-down volume-up brick-up brick-down
Let me know your thoughts! Thanks.
-
2013-11-26
GlusterFS Block Device Translator
Block device translator Block device translator (BD xlator) is a new translator added to GlusterFS recently which provides block backend for GlusterFS. This replaces the existing bd_map translator in GlusterFS that provided similar but very limited functionality. GlusterFS expects the underlying brick to be formatted with a POSIX compatible file system. BD xlator changes that […]

