-
2016-09-10
10 minutes introduction to Gluster Eventing Feature
Demo video is included in the end, or you can directly watch it on YoutubeGluster Eventing is the new feature as part of Gluster.Next
initiatives, it provides close to realtime notification and alerts for
the Gluster cluster state changes.Websockets APIs to consume events will be added later. Now we emit
events via another popular mechanism called “Webhooks”.(Many popular
products provide notifications via Webhooks Github, Atlassian,
Dropbox, and many more)Webhooks are similar to callbacks(over HTTP), on event Gluster will
call the Webhook URL(via POST) which is configured. Webhook is a web server
which listens on a URL, this can be deployed outside of the
Cluster. Gluster nodes should be able to access this Webhook server on
the configured port. We will discuss about adding/testing webhook
later.Example Webhook written in python,
from flask import Flask, request app = Flask(__name__) @app.route("/listen", methods=["POST"]) def events_listener(): gluster_event = request.json if gluster_event is None: # No event to process, may be test call return "OK" # Process gluster_event # { # "nodeid": NODEID, # "ts": EVENT_TIMESTAMP, # "event": EVENT_TYPE, # "message": EVENT_DATA # } return "OK" app.run(host="0.0.0.0", port=9000)
Eventing feature is not yet available in any of the releases, patch is
under review in upstream master(http://review.gluster.org/14248). If anybody interested in trying it
out can cherrypick the patch from review.gluster.orggit clone http://review.gluster.org/glusterfs cd glusterfs git fetch http://review.gluster.org/glusterfs refs/changes/48/14248/5 git checkout FETCH_HEAD git checkout -b <YOUR_BRANCH_NAME> ./autogen.sh ./configure make make installStart the Eventing using,
gluster-eventing start
Other commands available are stop, restart, reload and
status. gluster-eventing --help for more details.Now Gluster can send out notifications via Webhooks. Setup a web
server listening to a POST request and register that URL to Gluster
Eventing. Thats all.gluster-eventing webhook-add <MY_WEB_SERVER_URL>
For example, if my webserver is running at http://192.168.122.188:9000/listen
then register using,gluster-eventing webhook-add ``http://192.168.122.188:9000/listen``
We can also test if web server is accessible from all Gluster nodes
using webhook-test subcommand.gluster-eventing webhook-test http://192.168.122.188:9000/listen
With the initial patch only basic events are covered, I will add more
events once this patch gets merged. Following events are available
now.Volume Create Volume Delete Volume Start Volume Stop Peer Attach Peer Detach
Created a small demo to show this eventing feature, it uses Web server
which is included with the patch for Testing.(laptop hostname is sonne)/usr/share/glusterfs/scripts/eventsdash.py --port 8080
Login to Gluster node and start the eventing,
gluster-eventing start gluster-eventing webhook-add http://sonne:8080/listen
And then login to VM and run Gluster commands to probe/detach peer,
volume create, start etc and Observe the realtime notifications for
the same where eventsdash is running.Example,
ssh root@fvm1 gluster peer attach fvm2 gluster volume create gv1 fvm1:/bricks/b1 fvm2:/bricks/b2 force gluster volume start gv1 gluster volume stop gv1 gluster volume delete gv1 gluster peer detach fvm2
Demo also includes a Web UI which refreshes its UI automatically when
something changes in Cluster.(I am still fine tuning this UI, not yet
available with the patch. But soon will be available as seperate repo
in my github)FAQ:
-
Will this feature available in 3.8 release?
Sadly No. I couldn’t get this merged before 3.8 feature freeze 🙁
-
Is it possible to create a simple Gluster dashboard outside the
cluster?It is possible, along with the events we also need REST APIs to get
more information from cluster or to perform any action in cluster.
(WIP REST APIs are available here) -
Is it possible to filter only alerts or critical notifications?
Thanks Kotresh for the
suggestion. Yes it is possible to add event_type and event_group
information to the dict so that it can be filtered easily.(Not yet
available now, but will add this feature once this patch gets merged
in Master) -
Is documentation available to know more about eventing design and
internals?Design spec available here
(which discusses about Websockets, currently we don’t have
Websockets support). Usage documentation is available in the commit
message of the patch(http://review.gluster.org/14248).
Comments and Suggestions Welcome.
-
-
2015-09-10
Simulating Race Conditions
Tiering feature is introduced in Gluster 3.7 release. Geo-replication may not perform well with Tiering feature yet. Races can happen since Rebalance moves files from one brick to another brick(hot to cold and cold to hot), but the Changelog/Journal remails in old brick itself. We know there will be problems since each Geo-replication worker(per brick) processes Changelogs belonging to respective brick and sync the data independently. Sync happens as two step operation, Create entry in Slave with the GFID recorded in Changelog, then use Rsync to sync data(using GFID access)
To uncover the bugs we need to setup workload and run multiple times since issues may not happen always. But it is tedious to run multiple times with actual data. How about simulating/mocking it?
Let us consider simple case of Rebalance, A file “f1” is created in Brick1 and after some time it becomes hot and Rebalance moved it to Brick2.
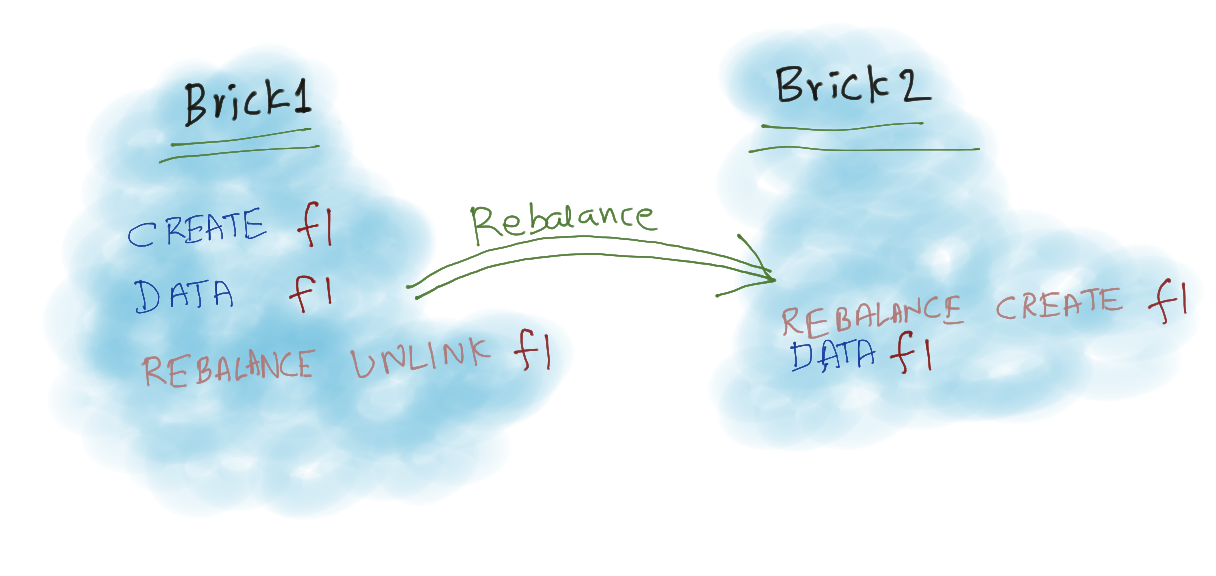
In Changelog we don’t capture the Rebalance Traffic, so in respective brick changelogs will contain,
# Brick1 Changelog CREATE 0945daec-6f8c-438e-9bbf-b2ebf07543ef f1 DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef # Brick2 Changelog DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef
If Brick1 worker processes fast, then Entry is created in Slave and Data Operation succeeds. Since Both the workers can independently, sequence of execution may be like
# Possible Sequence 1 [Brick1] CREATE 0945daec-6f8c-438e-9bbf-b2ebf07543ef f1 [Brick1] DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef [Brick2] DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef # Possible Sequence 2 [Brick2] DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef [Brick1] CREATE 0945daec-6f8c-438e-9bbf-b2ebf07543ef f1 [Brick1] DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef # Possible Sequence 3 [Brick1] CREATE 0945daec-6f8c-438e-9bbf-b2ebf07543ef f1 [Brick2] DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef [Brick1] DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef
We don’t have any problems with first and last sequence, But in second sequence Rsync will try to sync data before Entry Creation and Fails.
To solve this issue, we thought if we record CREATE from Rebalance traffic then it will solve this problem. So now brick Changelogs looks like,
# Brick1 Changelog CREATE 0945daec-6f8c-438e-9bbf-b2ebf07543ef f1 DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef # Brick2 Changelog CREATE 0945daec-6f8c-438e-9bbf-b2ebf07543ef f1 DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef
and possible sequences,
# Possible Sequence 1 [Brick1] CREATE 0945daec-6f8c-438e-9bbf-b2ebf07543ef f1 [Brick1] DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef [Brick2] CREATE 0945daec-6f8c-438e-9bbf-b2ebf07543ef f1 [Brick2] DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef # Possible Sequence 2 [Brick2] CREATE 0945daec-6f8c-438e-9bbf-b2ebf07543ef f1 [Brick1] CREATE 0945daec-6f8c-438e-9bbf-b2ebf07543ef f1 [Brick1] DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef [Brick2] DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef # and many more...
We do not have that problem, second CREATE will fail with EEXIST, we ignore it since it is safe error. But will this approach solves all the problems with Rebalance? When more FOPs added, it is very difficult to visualize or guess the problem.
To mock the concurrent workload, Collect sequence from each bricks Changelog and mix both the sequences. We should make sure that order in each brick remains same after the mix.
For example,
b1 = ["A", "B", "C", "D", "E"] b2 = ["F", "G"]
While mixing b2 in b1, for first element in b2 we can randomly choose a position in b1. Let us say random position we got is 2(Index is 2), and insert “F” in index 2 of b1
# before ["A", "B", "C", "D", "E"] # after ["A", "B", "F", "C", "D", "E"]
Now, to insert “G”, we should randomly choose anywhere after “F”. Once we get the sequence, mock the FOPs and compare with expected values.
I added a gist for testing following workload, it generates multiple sequences for testing.
# f1 created in Brick1, Rebalanced to Brick2 and then Unlinked # Brick1 Changelog CREATE 0945daec-6f8c-438e-9bbf-b2ebf07543ef f1 DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef # Brick2 Changelog CREATE 0945daec-6f8c-438e-9bbf-b2ebf07543ef f1 DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef UNLINK 0945daec-6f8c-438e-9bbf-b2ebf07543ef f1
Found two bugs.
- Trying to sync data after UNLINK(Which can be handled in Geo-rep by Rsync retry)
- Empty file gets created.
I just started simulating with Tiering + Geo-replication workload, I may encounter more problems with Renames(Simple, multiple and cyclic). Will update the results soon.
I am sharing the script since it can be easily modified to work with different workloads and to test other projects/components.
Let me know if this is useful. Comments and Suggestions Welcome.
-
2013-11-27
Effective GlusterFs monitoring using hooks
Let us imagine we have a GlusterFs monitoring system which displays list of volumes and its state, to show the realtime status, monitoring app need to query the GlusterFs in regular interval to check volume status, new volumes etc. Assume if the polling interval is 5 seconds then monitoring app has to run
gluster volume infocommand ~17000 times a day!How about maintaining a state file in each node? which gets updated after every new GlusterFs event(create, delete, start, stop etc).
In this blog post I am trying to explain the possibility of creating state file and using it.
As of today GlusterFs provides following hooks, which we can use to update our state file.
create delete start stop add-brick remove-brick set
How to use hooks
GlusterFs hooks present in
/var/lib/glusterd/hooks/1directory. Following example shows sending message to all users usingwallcommand when any new GlusterFs volume is created.Create a shell script
/var/lib/glusterd/hooks/1/create/post/SNotify.bashand make it executable. Whenever a volume is created GlusterFs executes all the executable scripts present in respective hook directory(Glusterfs executes only the scripts which filename starting with ‘S’)#!/bin/bash VOL= ARGS=$(getopt -l "volname:" -name "" $@) eval set -- "$ARGS" while true; do case $1 in --volname) shift VOL=$1 ;; *) shift break ;; esac shift done wall "Gluster Volume Created: $VOL";
Experimental project – GlusterWeb
This experimental project maintains a sqlite database
/var/lib/glusterd/nodestate/glusternodestate.dbwhich gets updated after any GlusterFs event. For example if a GlusterFs volume is created then it updates volumes table and also bricks table.This project depends on glusterfs-tools so install both projects.
git clone https://github.com/aravindavk/glusterfs-tools.git cd glusterfs-tools sudo python setup.py install git clone https://github.com/aravindavk/glusterfs-web.git cd glusterfs-web sudo python setup.py install
By running setup, this tool will install all the hooks which are required for monitoring. (cleanup is for removing all the hooks)
sudo glusternodestate setup
All set! now run
glusterwebto start webapp.sudo glusterweb
Web application starts running in
http://localhost:8080you can change the port using--portor-poption.sudo glusterweb -p 9000
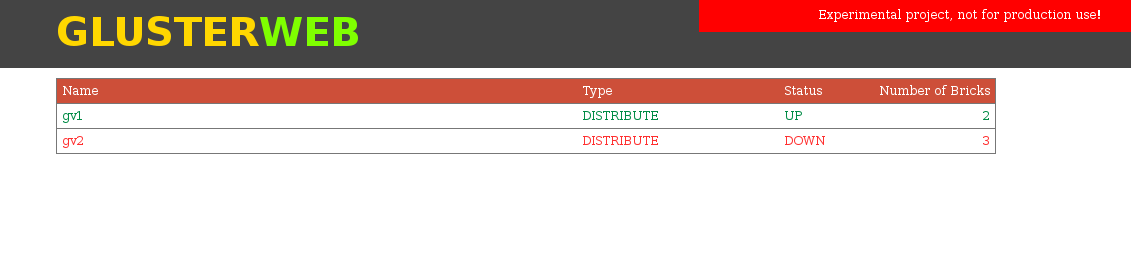
Initial version of web interface.
Future plans
Authentication: Option to provide username and password or access key while running glusterweb, For example
sudo glusterweb --username aravindavk --password somesecret # or sudo glusterweb --key secretonlyiknowMore gluster hooks support: we need more GlusterFs hooks for better monitoring(refer Problems below)
More GlusterFs features support: As a experiment UI only lists volumes, we need improved UI and support for different gluster features.
Actions support: Support for volume creation, adding/removing bricks etc.
REST api and SDK: Providing REST api for gluster operations.
Many more: Not yet planned 🙂
Problems
State file consistency: If glusterd goes down in the node then the database will have wrong details about node’s state. One workaround is to reset the database if glusterd is down using a cron job, when glusterd comes up, database will not gets updated and the database will have previous updated details. To prevent this we need a glusterfs hook for glusterd-start.
More hooks: As of today we don’t have hooks for volume down/up, brick down/up and other events. We need following hooks for effective monitoring glusterfs.(Add more if anything missing in the list)
glusterd-start peer probe peer detach volume-down volume-up brick-up brick-down
Let me know your thoughts! Thanks.