-
2016-09-15
GlusterFS 3.8.4 is available, Gluster users are advised to update
Even though the last release 3.8 was just two weeks ago, we’re sticking to the release schedule and have 3.8.4 ready for all our current and future users. As with all updates, we advise users of previous versions to upgrade to the latest and greatest. …
-
2016-09-13
Making gluster play nicely with others
These days hyperconverged strategies are everywhere. But when you think about it, sharing the finite resources within a physical host requires an effective means of prioritisation and enforcement. Luckily, the Linux kernel already provides an infrastructure for this in the shape of cgroups, and the interface to these controls is now simplified with systemd integration.So lets look at how you could use these capabilities to make Gluster a better neighbour in a collocated or hyperconverged model.First some common systemd terms, we should to be familiar with;slice : a slice is a concept that systemd uses to group together resources into a hierarchy. Resource constraints can then be applied to the slice, which defines- how different slices may compete with each other for resources (e.g. weighting)
- how resources within a slice are controlled (e.g. cpu capping)
unit : a systemd unit is a resource definition for controlling a specific system serviceNB. More information about control groups with systemd can be found hereIn this article, I’m keeping things simple by implementing a cpu cap on glusterfs processes. Hopefully, the two terms above are big clues, but conceptually it breaks down into two main steps;- define a slice which implements a CPU limit
- ensure gluster’s systemd unit(s) start within the correct slice.
So let’s look at how this is done.
Defining a slice
Slice definitions can be found under /lib/systemd/system, but systemd provides a neat feature where /etc/systemd/system can be used provide local “tweaks”. This override directory is where we’ll place a slice definition. Create a file called glusterfs.slice, containing;[Slice]
CPUQuota=200%CPUQuota is our means of applying a cpu limit on all resources running within the slice. A value of 200% defines a 2 cores/execution threads limit.Updating glusterd
Next step is to give gluster a nudge so that it shows up in the right slice. If you’re using RHEL7 or Centos7, cpu accounting may be off by default (you can check in /etc/systemd/system.conf). This is OK, it just means we have an extra parameter to define. Follow these steps to change the way glusterd is managed by systemd# cd /etc/systemd/system
# mkdir glusterd.service.d
# echo -e “[Service]\nCPUAccounting=true\nSlice=glusterfs.slice” > glusterd.service.d/override.confglusterd is responsible for starting the brick and self heal processes, so by ensuring glusterd starts in our cpu limited slice, we capture all of glusterd’s child processes too. Now the potentially bad news…this ‘nudge’ requires a stop/start of gluster services. If your doing this on a live system you’ll need to consider quorum, self heal etc etc. However, with the settings above in place, you can get gluster into the right slice by;# systemctl daemon-reload
# systemctl stop glusterd
# killall glusterfsd && killall glusterfs
# systemctl daemon-reload
# systemctl start glusterdYou can see where gluster is within the control group hierarchy by looking at it’s runtime settings# systemctl show glusterd | grep slice
Slice=glusterfs.slice
ControlGroup=/glusterfs.slice/glusterd.service
Wants=glusterfs.slice
After=rpcbind.service glusterfs.slice systemd-journald.socket network.target basic.targetor use the systemd-cgls command to see the whole control group hierarchy├─1 /usr/lib/systemd/systemd –switched-root –system –deserialize 19
├─glusterfs.slice
│ └─glusterd.service
│ ├─ 867 /usr/sbin/glusterd -p /var/run/glusterd.pid –log-level INFO
│ ├─1231 /usr/sbin/glusterfsd -s server-1 –volfile-id repl.server-1.bricks-brick-repl -p /var/lib/glusterd/vols/repl/run/server-1-bricks-brick-repl.pid
│ └─1305 /usr/sbin/glusterfs -s localhost –volfile-id gluster/glustershd -p /var/lib/glusterd/glustershd/run/glustershd.pid -l /var/log/glusterfs/glustershd.log
├─user.slice
│ └─user-0.slice
│ └─session-1.scope
│ ├─2075 sshd: root@pts/0
│ ├─2078 -bash
│ ├─2146 systemd-cgls
│ └─2147 less
└─system.sliceAt this point gluster is exactly where we want it!Time for some more systemd coolness 😉 The resource constraints that are applied by the slice are dynamic, so if you need more cpu, you’re one command away from getting it;# systemctl set-property glusterfs.slice CPUQuota=350% Try the ‘systemd-cgtop’ command to show the cpu usage across the complete control group hierarchy.Now if jumping straight into applying resource constraints to gluster is a little daunting, why not test this approach with a tool like ‘stress‘. Stress is designed to simply consume components of the system – cpu, memory, disk. Here’s an example .service file which uses stress to consume 4 cores[Unit]
Description=CPU soak task[Service]
Type=simple
CPUAccounting=true
ExecStart=/usr/bin/stress -c 4
Slice=glusterfs.slice[Install]
WantedBy=multi-user.targetNow you can tweak the service, and the slice with different thresholds before you move on to bigger things! Use stress to avoid stress 🙂And now the obligatory warning. Introducing any form of resource constraint may resort in unexpected outcomes especially in hyperconverged/collocated systems – so adequate testing is key.With that said…happy hacking 🙂
-
2016-09-10
10 minutes introduction to Gluster Eventing Feature
Demo video is included in the end, or you can directly watch it on YoutubeGluster Eventing is the new feature as part of Gluster.Next
initiatives, it provides close to realtime notification and alerts for
the Gluster cluster state changes.Websockets APIs to consume events will be added later. Now we emit
events via another popular mechanism called “Webhooks”.(Many popular
products provide notifications via Webhooks Github, Atlassian,
Dropbox, and many more)Webhooks are similar to callbacks(over HTTP), on event Gluster will
call the Webhook URL(via POST) which is configured. Webhook is a web server
which listens on a URL, this can be deployed outside of the
Cluster. Gluster nodes should be able to access this Webhook server on
the configured port. We will discuss about adding/testing webhook
later.Example Webhook written in python,
from flask import Flask, request app = Flask(__name__) @app.route("/listen", methods=["POST"]) def events_listener(): gluster_event = request.json if gluster_event is None: # No event to process, may be test call return "OK" # Process gluster_event # { # "nodeid": NODEID, # "ts": EVENT_TIMESTAMP, # "event": EVENT_TYPE, # "message": EVENT_DATA # } return "OK" app.run(host="0.0.0.0", port=9000)
Eventing feature is not yet available in any of the releases, patch is
under review in upstream master(http://review.gluster.org/14248). If anybody interested in trying it
out can cherrypick the patch from review.gluster.orggit clone http://review.gluster.org/glusterfs cd glusterfs git fetch http://review.gluster.org/glusterfs refs/changes/48/14248/5 git checkout FETCH_HEAD git checkout -b <YOUR_BRANCH_NAME> ./autogen.sh ./configure make make installStart the Eventing using,
gluster-eventing start
Other commands available are stop, restart, reload and
status. gluster-eventing --help for more details.Now Gluster can send out notifications via Webhooks. Setup a web
server listening to a POST request and register that URL to Gluster
Eventing. Thats all.gluster-eventing webhook-add <MY_WEB_SERVER_URL>
For example, if my webserver is running at http://192.168.122.188:9000/listen
then register using,gluster-eventing webhook-add ``http://192.168.122.188:9000/listen``
We can also test if web server is accessible from all Gluster nodes
using webhook-test subcommand.gluster-eventing webhook-test http://192.168.122.188:9000/listen
With the initial patch only basic events are covered, I will add more
events once this patch gets merged. Following events are available
now.Volume Create Volume Delete Volume Start Volume Stop Peer Attach Peer Detach
Created a small demo to show this eventing feature, it uses Web server
which is included with the patch for Testing.(laptop hostname is sonne)/usr/share/glusterfs/scripts/eventsdash.py --port 8080
Login to Gluster node and start the eventing,
gluster-eventing start gluster-eventing webhook-add http://sonne:8080/listen
And then login to VM and run Gluster commands to probe/detach peer,
volume create, start etc and Observe the realtime notifications for
the same where eventsdash is running.Example,
ssh root@fvm1 gluster peer attach fvm2 gluster volume create gv1 fvm1:/bricks/b1 fvm2:/bricks/b2 force gluster volume start gv1 gluster volume stop gv1 gluster volume delete gv1 gluster peer detach fvm2
Demo also includes a Web UI which refreshes its UI automatically when
something changes in Cluster.(I am still fine tuning this UI, not yet
available with the patch. But soon will be available as seperate repo
in my github)FAQ:
-
Will this feature available in 3.8 release?
Sadly No. I couldn’t get this merged before 3.8 feature freeze 🙁
-
Is it possible to create a simple Gluster dashboard outside the
cluster?It is possible, along with the events we also need REST APIs to get
more information from cluster or to perform any action in cluster.
(WIP REST APIs are available here) -
Is it possible to filter only alerts or critical notifications?
Thanks Kotresh for the
suggestion. Yes it is possible to add event_type and event_group
information to the dict so that it can be filtered easily.(Not yet
available now, but will add this feature once this patch gets merged
in Master) -
Is documentation available to know more about eventing design and
internals?Design spec available here
(which discusses about Websockets, currently we don’t have
Websockets support). Usage documentation is available in the commit
message of the patch(http://review.gluster.org/14248).
Comments and Suggestions Welcome.
-
-
2016-09-07
Gluster Container Demo Videos on “Gluster as a Persistent Data Store for Containers…. “
Recently I got a chance to consolidate the Demo videos which covers how GlusterFS can be used in Docker, kubernetes and Openshift. I have placed everything in single channel for better tracking. The demo videos are analogous to previously published blog entries in this space. Here is a brief description…
-
2016-09-02
delete, info, config : GlusterFS Snapshots CLI Part 2
Now that we know how to create GlusterFS snapshots, it will be handy to know, how to delete them as well. Right now I have a cluster with two volumes at my disposal. As can be seen below, each volume has 1 brick.# gluster volume infoVolume Name: test_v…
-
2016-08-30
Run Gluster systemd containers [without privileged mode] in Fedora/CentOS
In previous blog, I explained a method ( oci-systemd-hook) to run systemd gluster containers using oci-system-hook in a locked down mode. Today we will discuss about how to run gluster systemd containers without ‘privilege’ mode !! Awesome .. Isnt it ? I owe this blog to few people latest being…
-
2016-08-26
Possible configurations of GlusterFS in Kubernetes/OpenShift setup
In previous blog posts we discussed, how to use GlusterFS as a persistent storage in Kubernetes and Openshift. In nutshell, the GlusterFS can be deployed/used in a kubernetes/openshift environment as : *) Contenarized GlusterFS ( Pod ) *) GlusterFS as Openshift service and Endpoint (Service and Endpoint). *) GlusterFS volume…
-
2016-08-24
[Coming Soon] Dynamic Provisioning of GlusterFS volumes in Kubernetes/Openshift!!
In this context I am talking about the dynamic provisioning capability of ‘glusterfs’ plugin in Kubernetes/Openshift. I have submitted a Pull Request to Kubernetes to add this functionality for GlusterFS. At present, there is no existing network storage provisioners in kubernetes eventhough there are cloud providers. The idea here is…
-
2016-06-14
GlusterFS Snapshots And Their Prerequisites
Long time, no see huh!!! This post has been pending on my part for a while now, partly because I was busy and partly because I am that lazy. But it’s a fairly important post as it talks about snapshotting the GlusterFS volumes. So what are these snapsh…
-
2016-04-18
Deduplication Part 1: Rabin Karp for Variable Chunking
This is first post in a series of blog posts where we will discuss deduplication in a distributed data system. Here we will discuss different types of deduplication and various approaches taken in a distributed data systems to get optimum performance and storage efficiency. But first basics of deduplication! “Data deduplication (often called “intelligent compression” […]

-
2016-03-29
Persistent Volume and Claim in OpenShift and Kubernetes using GlusterFS Volume Plugin
OpenShift is a platform as a service product from Red Hat. The software that runs the service is open-sourced under the name OpenShift Origin, and is available on GitHub. OpenShift v3 is a layered system designed to expose underlying Docker and Kubernetes concepts as accurately as possible, with a focus…
-
2016-02-22
Gluster Takes Its Show on the Road
 The last week of January and the first week of February were packed with events and meetings.
The last week of January and the first week of February were packed with events and meetings.This blog contains my observations, opinions, and ideas in the hope that they will be useful or at least interesting for some.
CentOS Dojo in Brussels
The day before FOSDEM starts, the CentOS project organizes a community
meetup in the form of their Dojos at an IBM office in Brussels. Because
Gluster is participating in the CentOS Storage SIG (special interest group), I was asked to present something. My talk had a good
participation, asking about different aspects of the goals that the
Storage SIG has.Many people are interested in the Storage SIG, mainly other SIGs that
would like to consume the packages getting produced. There is
also increasing interest from upcoming architectures to get Gluster
running on their new hardware (Aarch64 and ppc64le). The CentOS team is
working on getting the hardware in the build infrastructure and testing
environment, the Gluster packages will be one of the first SIG projects
going to use that.I was surprised to see two engineers from Nutanix attend
the talk. They were very attentive when others asked about VM workloads
and hyper-convergence-related topics.The CentOS team maintains a Gluster environment for virtual machines. It
is possible for CentOS projects to request a VM, and this VM will be
located on their OpenNebula “cloud” backed by Gluster. This is a small
environment with four servers, connected over Infiniband. Gluster is setup
to use IPoIB, not using its native RDMA support. Currently, this is
running glusterfs-3.6 with a two-way replica, OpenNebula runs the VMs over
QEMU+libgfapi. In the future, this will most likely be replaced by a similar setup
based on oVirt.FOSDEM 2016
At FOSDEM, we had a very minimal booth/table. The 500 stickers that
Amye Scavarda brought and a bunch of ball pens imported by Humble and Kaushal
were handed out around noon on the second day. Lots of people were aware of
Gluster and many were not. We definitely need a better presence next
year, visitors should easily see that Gluster is about storage and not
only the good-looking ant. Kaushal and Humble wrote detailed
blog posts about FOSDEM already.Some users that knew about Gluster also had some questions about Ceph. I
unfortunately could not point them to a booth where experts were hanging
around. It would really be nice to have some Ceph people manning a
(maybe even shared) table. Interested users should get good advice on
picking the best storage solution for their needs, and of course we
would like then to try Gluster or Ceph in the first place. A good
suggestion for users is important to prevent disappointment and possibly
negative promotion.The talk I gave at FOSDEM attracted (a guestimated) 400-500 people.
The auditorium was huge, but “only” filled somewhere between 25-50% with
a lot of people arriving late, and some leaving a few minutes early.
After the talk, there were a lot of questions and we asked to move
the group of people to a little more remote location so that the next
presentation could start without the background noise. Kaleb helped in
answering some of the visitors questions, and we directed a few to the
guys at the Gluster booth as well. The talk seemed to have gone well, and I
got a request to present something at the next NLUUG conference.Gluster Developer Gatherings, Red Hat, Brno
This was mainly informal chats about different topics listed in this Google Doc. We encouraged each topic to add a link to an etherpad where notes
are kept. The presenters of the sessions are expected to send a summary
based on the notes to the (community) mailing lists, which I won’t cover here.Some notes that I made during conversations that were not really
planned:-
Richacl needed for multiprotocol support, Rajesh will post his
work-in-progress patches to Gerrit so that others can continue with
his start and get it in for glusterfs-3.8. (Michael Adam) -
QE will push downstream helper libraries for testing with distaf to
the upstream distaf framework repo or upstream tests repo. MS and
Jonathan are the main contacts for defining and enforcing an
“upstream first” process. “Secret sauce” tests will not become part
of upstream (like some performance things), but all basic
functionality should. At the moment we only catch basic functionality
problems downstream, when we test upstream we should find them
earlier and have more time to fix them, less chance in slipping
release dates.Downstream QA will ultimately consist out of running the upstream
distaf framework, upstream tests repo and downstream tests repo. -
Paolo Bonzini (KVM maintainer) and Kevin Wolf (QEMU/block maintainer)
are interested in improved Gluster support in QEMU. Not only
SEEK_DATA/SEEK_HOLE would be nice, but also something that makes it
possible to detect “allocated but zero-filled.” lseek() can not
detect this yet, it might be a suitable topic for discussion during
LSF/MM in April.One of the things that the libvirt team (requested by oVirt/RHEV)
asked about was support for “backup-volfile-server” support. This was
a question from Doron Fediuck at FOSDEM as well. It was the first time
I heard about it. Adding this seemed simple, and a train ride
from Brussels to Amsterdam was enough to get something working. I was
informed that someone already attempted this approach earlier… This
work was not shared with other Gluster developers, so the progress on
it was also not clear :-/ After searching for proposed patches, we
found that Prasanna did quite some work (patch v13) for this. He was
expected to arrive after the meetup with the virtualization team was planned.Kevin did send me a detailed follow-up (in Dutch!) after he reviewed
the current status of QEMU/gluster. There are five suggestions on his
list, I will follow-up on that later (plus Prasanna and gluster-devel@).Snapshots of VM images can be done already, but they would benefit
from reflink support. This most likely will require a REFLINK FOP in
Gluster, and the appropriate extensions to FUSE and libgfapi.
Something we might want to think about for after Gluster 4.0. -
Finally, I met Csaba Henk in real life. He will be picking up adding
support for Kerberos in the multitude of Gluster protocols. More
on that will follow at some point.
DevConf.cz
Unfortunately, there was no Gluster swag or stickers at DevConf.cz, but this time there
were Ceph items! It feels like the Ceph and Gluster community managers
should work a little closer together so that we’re evenly recognized at
events. The impressions that I have heard, was like “Gluster is a
project for community users, Ceph is what Red Hat promotes for storage
solutions.” I’m pretty sure that it is not the message we want to relay
to others. The talks on Ceph and Gluster at the event(s) were more
equally distributed, so maybe visitors did not notice it like I did.During the Gluster Workshop (and most of the conference), there was
very bad Internet connectivity. This made it very difficult for the
participants to download the Gluster packages for their distribution. So
instead of a very “do-it-yourself” workshop, it became more of a
presentation and demonstration. From the few people that had taken the
courage to open their laptops, only a handful of attendees managed to
create a Gluster volume and try it out. The attendees of the workshop
were quite knowledgeable, and did not hesitate to ask good questions.After the workshop, there were more detailed questions from users and
developers. Some about split-brain resolution and prevention, others
about (again) the “backup-volfile-server” ‘mount’ option for QEMU. We
definitely need to promote features like “policy based split-brain
resolution,” “arbiter volumes,” and “sharded volumes” much more. Many
users store VM images on Gluster and anything that helps improving the
performance and stability gets a lot of interest.Nir Soffer (working on oVirt/RHEV) wanted to discuss some more about
improving their support for Gluster. They currently use FUSE mounts and
should move to QEMU+libgfapi to improve performance and work around
difficulties with their usage of FUSE filesystems. At least two things
could use assistance from the Gluster team:- glusterfs-cli to be available for RHGS client systems
- Sanlock improvements to use libgfapi instead of a filesystem
Speaking to Heinz Mauelshagen (LVM/dm developer) about different aspects
of Gluster triggered a memory of something a FOSDEM visitor asked: Would
it be possible to have a tiered Gluster volume with a RAM-disk as “hot”
tier? This is not something we can do in Gluster now, but it seems
that dm-cache can be configured like this. dm-cache just needs a
block-device, and that can be created at boot. With some config-options
it is possible to setup dm-cache as a write-through cache. This is
definitely something I need to check out and relay back to the guy
asking this question (he’s in the interesting situation where they can
fill up all the RAM slots in their server if they want).Upstream testing the CentOS CI is available for many open source
projects. Gluster will be using this soon for regular distaf test runs,
and integration tests with other projects. NFS-Ganesha and Samba are
natural candidates for that, so I encouraged Michael and Guenter to
attend the CentOS CI talk by Brian Stinson.Because the (partial) sysadmins for the Gluster infrastructure (Jenkins,
Gerrit, others servers and services) have too little time to maintain
everything, OSAS suggested to use the expertise of the CentOS team.
Many of the CentOS core members are very experienced in maintaining many
servers and services, the Gluster community could probably move much of
the infrastructure to the CentOS project and benefit from their
expertise. KB Singh sent an email with notes from a meeting about this topic to the gluster-infra list. It is up to the Gluster community
to accept their assistance and enjoy a more stable infrastructure.Wow, did you really read this up to here?! Thanks 🙂
This article originally appeared on
community.redhat.com.
Follow the community on Twitter at
@redhatopen, and find us on
Facebook and
Google+. -
-
2015-11-26
Usenix LISA 2015 Tutorial on GlusterFS
I have been working in GlusterFS for quite some time now. As you might know that GlusterFS is an open source distributed file-system. What differentiate Gluster from other distributed file-system is its scale-out nature, data access without metad…
-
2015-10-20
Managing the World of the Small
 There is a growing discussion in the IT world about the ways in which we, as information technologists, will approach managing the world of the small.
There is a growing discussion in the IT world about the ways in which we, as information technologists, will approach managing the world of the small.There are two aspects of current technology that fall into this category of “small”–containers and the Internet of Things. Both technologies were the subject of two intriguing keynotes at the opening session of All Things Open yesterday.
It’s been no secret that Intel is keenly interested in the Internet of Things (IoT) of late, and Intel’s Director of Embedded Software in the Open Source Technology Center Mark Skarpness laid out a concise look at how the hardware computer company is approaching the promise of a world of interconnected IP devices.
Currently, there are three obstacles that Skarpness perceives as a barrier to IoT growth: a lack of knowledge in embedded systems, a lack of knowledge and implementation of best security, and determining the most efficient ways in which IoT devices can communicate with the cloud and each other. This last aspect is particularly tricky; presently, many IoT devices operate in a siloed fashion. one or many sensored devices will talk to a control device, which in turn will talk to master server in the cloud that will collect data or deliver optimized operation instructions. But Company X’s devices will usually only work with Company X’s systems. Not Company Y or Z. This situation has led to what some wags on the press have called “The CompuServe of Things.”
This is clearly a situation about which Skarpness and his colleagues are well aware, and he did not try to give it short shrift when he told his audience what the path to better IoT would be. Issues like connectivity and customization of IoT devices in terms of form factor and purpose were two major elements of Intel’s IoT plan moving forward, Skarpness said, along with the aforementioned need to lock such devices down.
It was the fourth element of Intel’s plan that particularly caught my attention: building control systems that provide device management within the unique IoT ecosystem. Not only are deployed IoT devices found in very high numbers (think swarm instead of farm), but they can also be hardware-frozen. If you have a number of sensors buried in the road, for example, you can’t just dig them out and update their onboard hardware. You may not even be able to update the software; some devices may be transmit-only, not receive.
Managing devices in such circumstances can be tricky at best. The numbers alone can be daunting; sensor-equipped devices can range in the tens of thousands and the amount of data produced can create a huge firehose of incoming data. Indeed, many of these issues may seem familiar to those wrestling with another “new” bit of technology: containers.
Like IoT devices, containers are also proving to be a challange to manage. Containers and the microservices they host are not so much managed as orchestrated, according to the next keynote speaker, Sarah Novotny, Head of Developer Relations at NGINX.
Novotny referenced Skarpness’ outline of IoT concerns in her discussion of how information technologists should be approaching the future.of technology. Novotny’s talk highlighted Alan Gopnik’s 2011 New Yorker article “The Information,” which decribed how people then viewed the influence of the Internet on their lives: “call them the Never-Betters, the Better-Nevers, and the Ever-Wasers.” Novotny skillfully weaved these terms into the ways in which we view current technologies, including containers.
For containers, the “Better-Nevers” would look at the problem of managing containers and highlight the huge complexities in dealing with app-centric tools that in some cases, may only have a mayfly-like lifespan. The “Never-Betters” may see the positive benefits of microservices and realize that their benefits will outweigh the costs.
This may very well be true, but whatever your outlook, the challange of maintaining a cohesive form of management in container or IoT space is very real. As powerful as tools like oVirt, RDO, and ManageIQ may be, they are designed for managing whole machines (real or virtual), not potentially millions of containers or inerconnected hardware devices. This is why you see such emphasis placed on projects like Atomic, which are a new step towards a world where managing the small is even more of a critical need than managing the large.
This is a case of art (as technology) imitating life. Our tools are becoming reflections of our biology: where untold billions of microsystems make up the macrosystems we call the life we see around us. The transition won’t be easy, but the path to this kind of system deployment seems clear. It is fortunate the innovation that’s inherent in open source will help speed things along.
This article originally appeared on
community.redhat.com.
Follow the community on Twitter at
@redhatopen, and find us on
Facebook and
Google+. -
2015-10-13
Introducing the OSAS Community Dashboard
Red Hat’s Open Source and Standards (OSAS) group, working with Bitergia, is capturing interesting data from some of the upstream projects with which Red Hat is deeply involved. On this page, you’ll find various vital signs from projects like oVirt, RDO, ManageIQ, and Gluster.
It’s useful for folks who are familiar with an open source project to be able to see, at a glance, the general trends for things like mailing list activity, IRC discussions, or how many bugs/issues are being opened and closed.
Why We Collect Statistics
Overall, you hope to see more developer activity in projects, an upward trend in mailing list discussions and participants, and a healthy number of issues being opened–and closed–in the project’s bug tracker. Over time, numbers can fill in an important part of the story of a project.
It is, however, worth noting that numbers can be misleading. A lull in mailing list activity might be a sign that a project is slowing–or it might just be a sign that developers are heads-down working and being less chatty than usual. (Or it’s vacation season.) Lots of chatter in IRC might be a sign that a project is busy, or they might be discussing the World Cup extensively. (Or both!)
What you don’t see in the charts is the nature of discussions, whether discussions are productive or not, and how much actual work is being accomplished. For that, we have to be involved in the projects on a day-in, day-out basis.
Apples and Oranges
Another word of warning before perusing the stats – comparing raw numbers for two dissimilar projects is not a valid way of measuring the health of two projects. For example, oVirt and RDO have different target audiences, and are at different stages of maturity. Comparing the growth in a “mature” community and a younger community is like comparing the vital signs and growth charts of a toddler and a young adult. If a toddler is showing rapid growth, that’s to be expected. You don’t really expect a 25-year-old to gain a few inches between checkups. (In fact, it’d be weird if they did–and possibly alarming!)
The only real way to judge a project’s health is by measuring it against itself over time, and knowing about the project’s long-term mission and goals.
More to Come
What you’re seeing on the dashboard today isn’t the final word on how we measure our project’s success. We’ll be continuing to look for ways to gather, and share, information about our projects. Have ideas? We’d love to hear from you!
This article originally appeared on
community.redhat.com.
Follow the community on Twitter at
@redhatopen, and find us on
Facebook and
Google+. -
2015-09-22
Docker Global Hack Day #3, Bangalore Edition
We organized Docker Global Hack Day at Red Hat Office on 19th Sep’15. Though there were lots RSVPs, the turn up for the event was less than expected. We started the day by showing the recording of kick-off event. The … Continue reading →
-
2015-09-10
Simulating Race Conditions
Tiering feature is introduced in Gluster 3.7 release. Geo-replication may not perform well with Tiering feature yet. Races can happen since Rebalance moves files from one brick to another brick(hot to cold and cold to hot), but the Changelog/Journal remails in old brick itself. We know there will be problems since each Geo-replication worker(per brick) processes Changelogs belonging to respective brick and sync the data independently. Sync happens as two step operation, Create entry in Slave with the GFID recorded in Changelog, then use Rsync to sync data(using GFID access)
To uncover the bugs we need to setup workload and run multiple times since issues may not happen always. But it is tedious to run multiple times with actual data. How about simulating/mocking it?
Let us consider simple case of Rebalance, A file “f1” is created in Brick1 and after some time it becomes hot and Rebalance moved it to Brick2.
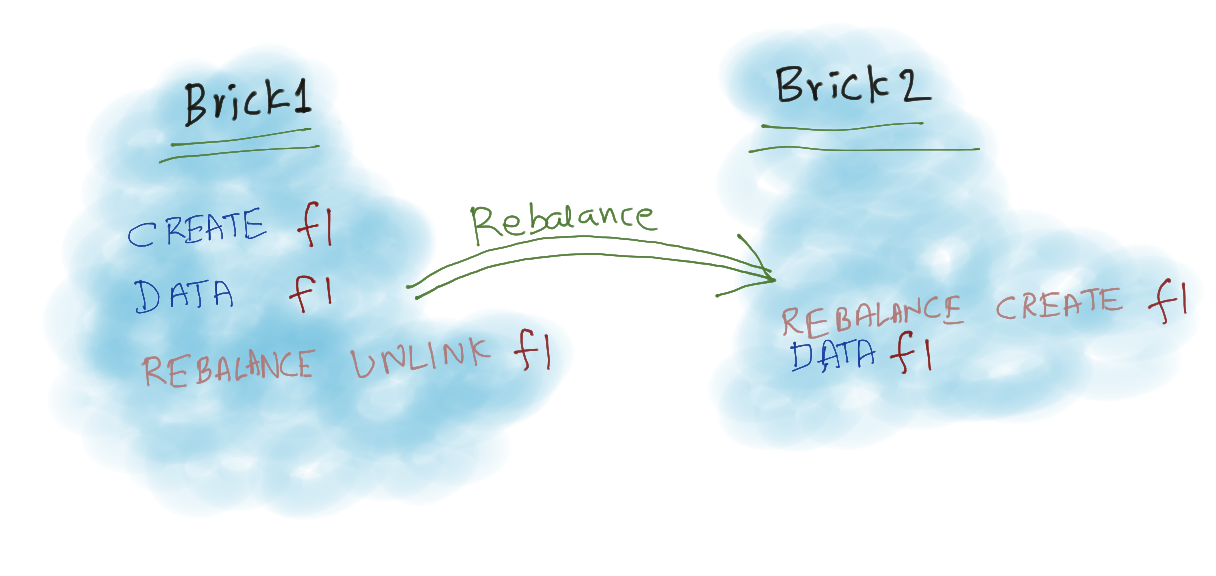
In Changelog we don’t capture the Rebalance Traffic, so in respective brick changelogs will contain,
# Brick1 Changelog CREATE 0945daec-6f8c-438e-9bbf-b2ebf07543ef f1 DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef # Brick2 Changelog DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef
If Brick1 worker processes fast, then Entry is created in Slave and Data Operation succeeds. Since Both the workers can independently, sequence of execution may be like
# Possible Sequence 1 [Brick1] CREATE 0945daec-6f8c-438e-9bbf-b2ebf07543ef f1 [Brick1] DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef [Brick2] DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef # Possible Sequence 2 [Brick2] DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef [Brick1] CREATE 0945daec-6f8c-438e-9bbf-b2ebf07543ef f1 [Brick1] DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef # Possible Sequence 3 [Brick1] CREATE 0945daec-6f8c-438e-9bbf-b2ebf07543ef f1 [Brick2] DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef [Brick1] DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef
We don’t have any problems with first and last sequence, But in second sequence Rsync will try to sync data before Entry Creation and Fails.
To solve this issue, we thought if we record CREATE from Rebalance traffic then it will solve this problem. So now brick Changelogs looks like,
# Brick1 Changelog CREATE 0945daec-6f8c-438e-9bbf-b2ebf07543ef f1 DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef # Brick2 Changelog CREATE 0945daec-6f8c-438e-9bbf-b2ebf07543ef f1 DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef
and possible sequences,
# Possible Sequence 1 [Brick1] CREATE 0945daec-6f8c-438e-9bbf-b2ebf07543ef f1 [Brick1] DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef [Brick2] CREATE 0945daec-6f8c-438e-9bbf-b2ebf07543ef f1 [Brick2] DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef # Possible Sequence 2 [Brick2] CREATE 0945daec-6f8c-438e-9bbf-b2ebf07543ef f1 [Brick1] CREATE 0945daec-6f8c-438e-9bbf-b2ebf07543ef f1 [Brick1] DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef [Brick2] DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef # and many more...
We do not have that problem, second CREATE will fail with EEXIST, we ignore it since it is safe error. But will this approach solves all the problems with Rebalance? When more FOPs added, it is very difficult to visualize or guess the problem.
To mock the concurrent workload, Collect sequence from each bricks Changelog and mix both the sequences. We should make sure that order in each brick remains same after the mix.
For example,
b1 = ["A", "B", "C", "D", "E"] b2 = ["F", "G"]
While mixing b2 in b1, for first element in b2 we can randomly choose a position in b1. Let us say random position we got is 2(Index is 2), and insert “F” in index 2 of b1
# before ["A", "B", "C", "D", "E"] # after ["A", "B", "F", "C", "D", "E"]
Now, to insert “G”, we should randomly choose anywhere after “F”. Once we get the sequence, mock the FOPs and compare with expected values.
I added a gist for testing following workload, it generates multiple sequences for testing.
# f1 created in Brick1, Rebalanced to Brick2 and then Unlinked # Brick1 Changelog CREATE 0945daec-6f8c-438e-9bbf-b2ebf07543ef f1 DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef # Brick2 Changelog CREATE 0945daec-6f8c-438e-9bbf-b2ebf07543ef f1 DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef UNLINK 0945daec-6f8c-438e-9bbf-b2ebf07543ef f1
Found two bugs.
- Trying to sync data after UNLINK(Which can be handled in Geo-rep by Rsync retry)
- Empty file gets created.
I just started simulating with Tiering + Geo-replication workload, I may encounter more problems with Renames(Simple, multiple and cyclic). Will update the results soon.
I am sharing the script since it can be easily modified to work with different workloads and to test other projects/components.
Let me know if this is useful. Comments and Suggestions Welcome.
-
2015-08-19
Welcome to the New Gluster Community Lead
The Open Source and Standards team in Red Hat is very pleased to announce the addition of a new team member: Amye Scavarda, who will be taking the role of GlusterFS Community Lead.
Amye’s journey to the GlusterFS Project could arguably be said to hav…
-
2015-08-18
Thanking Oh-My-Vagrant contributors for version 1.0.0
The Oh-My-Vagrant project became public about one year ago and at the time it was more of a fancy template than a robust project, but 188 commits (and counting) later, it has gotten surprisingly useful and mature. james@computer:~/code/oh-my-vagrant$ git rev-list … Continue reading →

-
2015-07-31
Build your own NAS with OpenMediaVault
OpenMediaVault is a Debian based special purpose Linux Distribution to build a Network Attached Storage (NAS) System. It provides an easy to use web-based interface, Multilanguage support, Volume Management, Monitoring and a plugin system to extend it …