-
2014-10-18
Hacking out an Openshift app
I had an itch to scratch, and I wanted to get a bit more familiar with Openshift. I had used it in the past, but it was time to have another go. The app and the code are now available. … Continue reading →

-
2014-10-10
Continuous integration for Puppet modules
I just patched puppet-gluster and puppet-ipa to bring their infrastructure up to date with the current state of affairs… What’s new? Better README’s Rake syntax checking (fewer oopsies) CI (testing) with travis on git push (automatic testing for everyone) Use … Continue reading →

-
2014-10-07
Gluster Volume
GlusterFS
GlusterFS is an open source distributed file system. It incorporates automatic fail-over as a primary feature. All of this is accomplished without a centralized metadata server. Which also guarantees no single point of failure.
The detail documentation and getting started document can be found at Gluster.org. In this article I want to give an overview of Gluster so that you can understand GlusterFS volume snapshot better.
Let’s say you have some machines (or virtual machines) where you want to host GlusterFS. So the first thing you want to install is a POSIX compliant operating system, e.g. Fedora, CentOS, RHEL, etc. Install GlusterFS server on all these machines. Click here to get the detailed instruction on how to install GlusterFS. Once GlusterFS server is installed on each machine you have to start the server. Run the following command to start the GlusterFS server:
service glusterd start
Or, start the server using the following command:
glusterd
Now, you have multiple GlusterFS servers, but they are not part of the Gluster “Trusted Storage Pool” yet. All the servers should be part of the “Trusted Storage Pool” before they can be accessed. Lets say you have 3 servers, Host1, Host2, and Host3. Run the following command to add them to the Gluster Trusted Storage Pool.
[root@Host1]# gluster peer probe Host2
peer probe: successNow, Host1 and Host2 are in the Trusted Storage Pool. You can check the status of the peer probe using the peer status command.
[root@Host1]# gluster peer status
Number of Peers: 1
Hostname: Host2
Uuid: 3b51894a-6cc1-43d0-a996-126a347056c8
State: Peer in Cluster (Connected)If you have any problems during the peer probe, make sure that your firewall is not blocking Gluster ports. Preferably, your storage environment should be located on a safe segment of your network where firewall is not necessary. In the real world, that simply isn’t possible for all environments. If you are willing to accept the potential performance loss of running a firewall, you need to know the following. Gluster makes use of ports 24007 for the Gluster Daemon, 24008 for Infiniband management (optional unless you are using IB), and one port for each brick in a volume. So, for example, if you have 4 bricks in a volume, port 49152 – 49155 would be used . Gluster uses ports 34865 – 34867 for the inline Gluster NFS server. Additionally, port 111 is used for portmapper, and should have both TCP and UDP open.
Once Host1 and Host2 are part of the Trusted Storage Pool you have to add Host3 to the trusted storage pool. You should run the same gluster peer probe command from either Host1 or Host2 to add Host3 to the Trusted Storage Pool. You will see the following output when you check the peer status:
[root@Host1]# gluster peer status
Number of Peers: 2
Hostname: Host2
Uuid: 3b51894a-6cc1-43d0-a996-126a347056c8
State: Peer in Cluster (Connected)
Hostname: Host3
Uuid: fa751bde-1f34-4d80-a59e-fec4113ba8ea
State: Peer in Cluster (Connected)Now, you have a Trusted Storage Pool with multiple servers or nodes, but still we are not ready for serving files from the trusted storage pool. GlusterFS volume is the unified namespace through which an user can access his/her files on the distributed storage. A Trusted Storage Pool can host multiple volumes. And each volume is made up of one or more bricks. The brick provides a mapping between the local file-system and the Gluster volume.
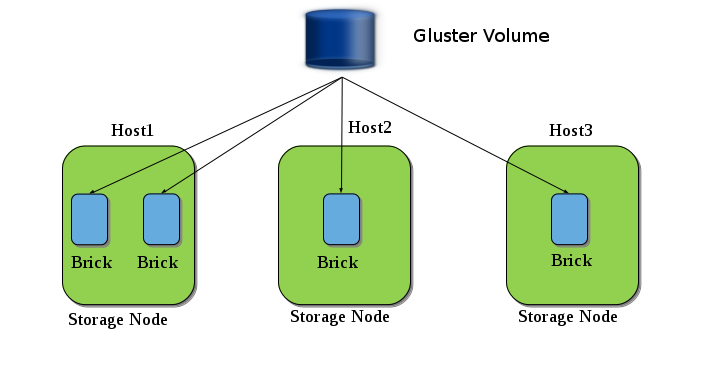
The above diagram shows an example of Gluster volume. Here we have three nodes (Host1, Host2 and Host3) and a Gluster Volume is created from the bricks present in those nodes.
Until now we have learned how to create a Trusted Pool, and now to create a volume you need to create bricks. These bricks can be a simple directory in your storage node, but to make use of snapshot feature these bricks have to adhere to some guidelines. In this document I provide you those guidelines and will take you through an example setup.
See guidelines for creating snapshot supportable volumes.
-
2014-10-07
What’s that bug to you? GlusterFS bug priority meeting
What’s that bug worth? One of the values of open source and open development is the impact of Community involvement. That involvement takes many forms, code development, innovation and evangelism, guidance for new users and solutions and identifying bugs. Finding and fixing problems in existing code is incredibly valuable in building production ready systems. And …Read more
-
2014-10-05
GlusterFS 3.5.3beta1 has been released for testing
The first beta for GlusterFS 3.5.3 is now available for download.Packages for different distributions will land on the download server over the next few days. When packages become available, the package maintainers will send a notification to the glust…
-
2014-10-05
GlusterFS 3.5.3beta1 has been released for testing
The first beta for GlusterFS 3.5.3 is now available for download.Packages for different distributions will land on the download server over the next few days. When packages become available, the package maintainers will send a notification to the glust…
-
2014-09-30
Gluster, CIFS, ZFS – kind of part 2
A while ago I put together a post detailing the installation and configuration of 2 hosts running glusterfs, which was then presented as CIFS based storage. http://jonarcher.info/2014/06/windows-cifs-fileshares-using-glusterfs-ctdb-highly-available-data/ This post gained a bit of interest through the comments and social networks, one of the comments I got was from John Mark Walker suggesting I look at the …read more
The post Gluster, CIFS, ZFS – kind of part 2 appeared first on Jon Archer.
-
2014-09-03
Introducing: Oh My Vagrant!
If you’re a reader of my code or of this blog, it’s no secret that I hack on a lot of puppet and vagrant. Recently I’ve fooled around with a bit of docker, too. I realized that the vagrant, environments … Continue reading →

-
2014-08-27
Rough data density calculations
Seagate has just publicly announced 8TB HDD’s in a 3.5″ form factor. I decided to do some rough calculations to understand the density a bit better… Note: I have decided to ignore the distinction between Terabytes (TB) and Tebibytes (TiB), since … Continue reading →

-
2014-08-13
Upgrade CentOS 6 to 7 with Upgrade Tools
I decided to try the upgrade process from EL 6 to 7 on the servers I used in my previous blog post “Windows (CIFS) fileshares using GlusterFS and CTDB for Highly available data” Following the instructions here I found the process fairly painless. However there were 1 or two little niggles which caused various issues which …read more
The post Upgrade CentOS 6 to 7 with Upgrade Tools appeared first on Jon Archer.
-
2014-07-21
Testers needed for GlusterFS 3.5.2beta1
GlusterFS 3.5.2beta1 has just been released. This is the first beta to allow users to verify the fixes for the bugs that were reported. See the bug reports below for more details on how to test and confirm the fix (or not). This is a bugfix only releas…
-
2014-06-30
Windows (CIFS) fileshares using GlusterFS and CTDB for Highly available data
This tutorial will walk through the setup and configuration of GlusterFS and CTDB to provide highly available file storage via CIFS. GlusterFS is used to replicate data between multiple servers. CTDB provides highly available CIFS/Samba functionality. Prerequisites: 2 servers (virtual or physical) with RHEL 6 or derivative (CentOS, Scientific Linux). When installing create a partition …read more
The post Windows (CIFS) fileshares using GlusterFS and CTDB for Highly available data appeared first on Jon Archer.
-
2014-06-24
glusterfs-3.5.1 has been released
On Tue, Jun 24, 2014 at 03:15:58AM -0700, Gluster Build System wrote:> > > SRC: http://bits.gluster.org/pub/gluster/glusterfs/src/glusterfs-3.5.1.tar.gz> > This release is made off jenkins-release-73Many thanks to everyone how tested the…
-
2014-06-04
Hiera data in modules and OS independent puppet
Earlier this year, R.I.Pienaar released his brilliant data in modules hack, a few months ago, I got the chance to start implementing it in Puppet-Gluster, and today I have found the time to blog about it. What is it? R.I.’s … Continue reading →

-
2014-05-25
glusterfs-3.5.1beta released
Reposting the email to the Gluster Users and Developers mailinglists.On Sat, 24 May, 2014 at 11:34:36PM -0700, Gluster Build System wrote:> > SRC: http://bits.gluster.org/pub/gluster/glusterfs/src/glusterfs-3.5.1beta.tar.gzThis beta release is i…
-
2014-05-13
Vagrant on Fedora with libvirt (reprise)
Vagrant has become the de facto tool for devops. Faster iterations, clean environments, and less overhead. This isn’t an article about why you should use Vagrant. This is an article about how to get up and running with Vagrant on … Continue reading →

-
2014-05-06
Keeping git submodules in sync with your branches
This is a quick trick for making working with git submodules more magic. One day you might find that using git submodules is needed for your project. It’s probably not necessary for everyday hacking, but if you’re glue-ing things together, … Continue reading →

-
2014-05-05
An OpenStack Storage Hackathon
With technologies around Open Software-defined Storage emerging as the way to get things done in the cloud, we’ve noticed strong interest in how to take advantage of this emerging software space. Storage is changing from the proprietary, expensive box in the corner to a set of APIs and open source software deployed in a scale-out …Read more
-
2014-04-20
GlusterFS VFS plugin for Samba
Here are the topics this blog is going to cover. Samba Server Samba VFS Libgfapi GlusterFS VFS plugin for Samba and libgfapi Without GlusterFS VFS plugin FUSE mount vs VFS plugin About Samba Server: Samba server runs on Unix and … Continue reading →

-
2014-04-15
Configuring autofs for GlusterFS 3.5
GlusterFS 3.5 has not been released yet, but that should happen hopefully anytime soon (currently in beta). The RPM-packaging in this version has changed a little, and now offers a
glusterfs-clipackage. This package mainly contains theglustercommandline interface (and pulls in any dependencies).On of the very useful things that is now made possible, is to list the available volumes on Gluster Storge Servers. This similar functionality is used by the
/etc/auto.netscript to list NFS-exports that are available for mounting. Theauto.netscript is by default enabled after installing and startingautofs:# yum install autofs
# systemctl enable autofs.service
# systemctl start autofs.serviceChecking, and mounting NFS-exports is made as easy as:
$ ls /net/nfs-server.example.net
archive media mock_cache olpc
$ ls /net/nfs-server.example.net/mock_cache/fedora-rawhide-armhfp/
yum_cacheMaking this functionality available for Gluster Volumes is simple, just follow these steps:
-
install the
glustercommand# yum install glusterfs-cli -
save the file below as
/etc/auto.glfs#!/bin/bash
# /etc/auto.glfs -- based on /etc/auto.net
#
# This file must be executable to work! chmod 755!
#
# Look at what a host is exporting to determine what we can mount.
# This is very simple, but it appears to work surprisingly well
#
key="$1"
# add "nosymlink" here if you want to suppress symlinking local filesystems
# add "nonstrict" to make it OK for some filesystems to not mount
opts="-fstype=glusterfs,nodev,nosuid"
for P in /usr/local/bin /usr/local/sbin /usr/bin /usr/sbin /bin /sbin
do
if [ -x ${P}/gluster ]
then
GLUSTER_CLI=${P}/gluster
break
fi
done
[ -x ${GLUSTER_CLI} ] || exit 1
${GLUSTER_CLI} --remote-host="${key}" volume list | \
awk -v key="$key" -v opts="$opts" -- '
BEGIN { ORS=""; first=1 }
{ if (first) { print opts; first=0 }; print " \\\n\t/" $1, key ":/" $1 }
END { if (!first) print "\n"; else exit 1 }' | \
sed 's/#/\\#/g' -
make the script executable
# chmod 0755 /etc/auto.glfs -
add an automount point to the autofs configuration
# echo /glfs /etc/auto.glfs > /etc/auto.master.d/glfs.autofs -
reload the autofs configuration
# systemctl reload autofs.service
After this,
autofsshould have created a new/glfsdirectory. The directory itself is empty, but als /glfs/gluster.example.netwill show all the available volumes on the gluster.example.net server. These volumes can now be accessed through the autofs mountpoint. When the volumes are not used anymore, autofs will automatically unmount them after a timeout. -
{kind=link}