-
2014-10-31
GlusterFS 3.6.0 is Alive!
Just in time for Halloween, GlusterFS 3.6.0 has been released. The newest release, as you would expect, is full of new features and new elements for stability. GlusterFS, as you may know, is a general-purpose scale out distributed file system. It aggregates storage exports over network interconnects provide a single unified namespace, is stackable and …Read more
-
2014-10-31
GlusterFS at OpenStack Summit, Paris
A few of us will be attending the OpenStack Summit in Paris next week. OpenStack Storage continues to be an area of interest for GlusterFS and we will be investigating further integration possibilities of GlusterFS with the broad OpenStack ecosystem as we attend the summit. As you might be aware, GlusterFS already is tightly integrated …Read more
-
2014-10-30
Gluster Night Paris
Hey folks We’re having a Gluster event in Paris on 4-November, to get together and celebrate a number of new technologies, including the GlusterFS 3.6.0 release. Sign up here: http://www.eventbrite.com/e/inscription-gluster-night-paris-10413255327?aff=es2&rank=0 Our agenda is pretty packed: Event opens at 18:00 18:00 Drinks, snacks and chats 18:15 : Overview of 3.6.0 new features 18:25 …Read more
-
2014-10-23
2014 “State of Gluster” poll
As we roll towards the release of GlusterFS 3.6.0, it seemed a good time to find out what and how you are using GlusterFS. To that end, we’ve got a short poll up at https://www.surveymonkey.com/s/gluster2014, which should be pretty quick for you to take. This is completely anonymous, unless you choose to opt in to allow …Read more
-
2014-10-22
Gluster Volume Snapshot Howto
This article will provide details on how to configure GlusterFS volume to make use of Gluster Snapshot feature. As we have already discussed earlier that Gluster Volume Snapshot is based of thinly provisioned logical volume (LV). Therefore here I wi…
-
2014-10-18
Hacking out an Openshift app
I had an itch to scratch, and I wanted to get a bit more familiar with Openshift. I had used it in the past, but it was time to have another go. The app and the code are now available. … Continue reading →

-
2014-10-10
Continuous integration for Puppet modules
I just patched puppet-gluster and puppet-ipa to bring their infrastructure up to date with the current state of affairs… What’s new? Better README’s Rake syntax checking (fewer oopsies) CI (testing) with travis on git push (automatic testing for everyone) Use … Continue reading →

-
2014-10-07
Gluster Volume
GlusterFS
GlusterFS is an open source distributed file system. It incorporates automatic fail-over as a primary feature. All of this is accomplished without a centralized metadata server. Which also guarantees no single point of failure.
The detail documentation and getting started document can be found at Gluster.org. In this article I want to give an overview of Gluster so that you can understand GlusterFS volume snapshot better.
Let’s say you have some machines (or virtual machines) where you want to host GlusterFS. So the first thing you want to install is a POSIX compliant operating system, e.g. Fedora, CentOS, RHEL, etc. Install GlusterFS server on all these machines. Click here to get the detailed instruction on how to install GlusterFS. Once GlusterFS server is installed on each machine you have to start the server. Run the following command to start the GlusterFS server:
service glusterd start
Or, start the server using the following command:
glusterd
Now, you have multiple GlusterFS servers, but they are not part of the Gluster “Trusted Storage Pool” yet. All the servers should be part of the “Trusted Storage Pool” before they can be accessed. Lets say you have 3 servers, Host1, Host2, and Host3. Run the following command to add them to the Gluster Trusted Storage Pool.
[root@Host1]# gluster peer probe Host2
peer probe: successNow, Host1 and Host2 are in the Trusted Storage Pool. You can check the status of the peer probe using the peer status command.
[root@Host1]# gluster peer status
Number of Peers: 1
Hostname: Host2
Uuid: 3b51894a-6cc1-43d0-a996-126a347056c8
State: Peer in Cluster (Connected)If you have any problems during the peer probe, make sure that your firewall is not blocking Gluster ports. Preferably, your storage environment should be located on a safe segment of your network where firewall is not necessary. In the real world, that simply isn’t possible for all environments. If you are willing to accept the potential performance loss of running a firewall, you need to know the following. Gluster makes use of ports 24007 for the Gluster Daemon, 24008 for Infiniband management (optional unless you are using IB), and one port for each brick in a volume. So, for example, if you have 4 bricks in a volume, port 49152 – 49155 would be used . Gluster uses ports 34865 – 34867 for the inline Gluster NFS server. Additionally, port 111 is used for portmapper, and should have both TCP and UDP open.
Once Host1 and Host2 are part of the Trusted Storage Pool you have to add Host3 to the trusted storage pool. You should run the same gluster peer probe command from either Host1 or Host2 to add Host3 to the Trusted Storage Pool. You will see the following output when you check the peer status:
[root@Host1]# gluster peer status
Number of Peers: 2
Hostname: Host2
Uuid: 3b51894a-6cc1-43d0-a996-126a347056c8
State: Peer in Cluster (Connected)
Hostname: Host3
Uuid: fa751bde-1f34-4d80-a59e-fec4113ba8ea
State: Peer in Cluster (Connected)Now, you have a Trusted Storage Pool with multiple servers or nodes, but still we are not ready for serving files from the trusted storage pool. GlusterFS volume is the unified namespace through which an user can access his/her files on the distributed storage. A Trusted Storage Pool can host multiple volumes. And each volume is made up of one or more bricks. The brick provides a mapping between the local file-system and the Gluster volume.
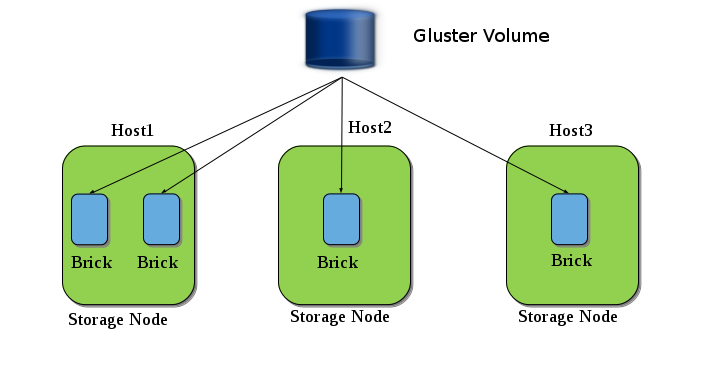
The above diagram shows an example of Gluster volume. Here we have three nodes (Host1, Host2 and Host3) and a Gluster Volume is created from the bricks present in those nodes.
Until now we have learned how to create a Trusted Pool, and now to create a volume you need to create bricks. These bricks can be a simple directory in your storage node, but to make use of snapshot feature these bricks have to adhere to some guidelines. In this document I provide you those guidelines and will take you through an example setup.
See guidelines for creating snapshot supportable volumes.
-
2014-10-07
What’s that bug to you? GlusterFS bug priority meeting
What’s that bug worth? One of the values of open source and open development is the impact of Community involvement. That involvement takes many forms, code development, innovation and evangelism, guidance for new users and solutions and identifying bugs. Finding and fixing problems in existing code is incredibly valuable in building production ready systems. And …Read more
-
2014-10-05
GlusterFS 3.5.3beta1 has been released for testing
The first beta for GlusterFS 3.5.3 is now available for download.Packages for different distributions will land on the download server over the next few days. When packages become available, the package maintainers will send a notification to the glust…
-
2014-10-05
GlusterFS 3.5.3beta1 has been released for testing
The first beta for GlusterFS 3.5.3 is now available for download.Packages for different distributions will land on the download server over the next few days. When packages become available, the package maintainers will send a notification to the glust…
-
2014-10-01
Adding voices: Support the Ada Initiative
Diversity is important to communities. Diversity adds new ideas, new concepts, innovative approaches and unique values. Open source thrives on those same things, and open source communities need to recognize and strive to increase their own diversity. Today, I’d like to share “A Challenge to the Open Storage Community” from Sage Weil. Sage is talking specifically …Read more
-
2014-09-30
Gluster, CIFS, ZFS – kind of part 2
A while ago I put together a post detailing the installation and configuration of 2 hosts running glusterfs, which was then presented as CIFS based storage. http://jonarcher.info/2014/06/windows-cifs-fileshares-using-glusterfs-ctdb-highly-available-data/ This post gained a bit of interest through the comments and social networks, one of the comments I got was from John Mark Walker suggesting I look at the …read more
The post Gluster, CIFS, ZFS – kind of part 2 appeared first on Jon Archer.
-
2014-09-22
Experimenting with Ceph support for NFS-Ganesha
NFS-Ganesha is a user-space NFS-server that is available in Fedora. It contains several plugins (FSAL, File System Abstraction Layer) for supporting different storage backends. Some of the more interesting are:
- VFS: a normal mounted filesystem
- GLUSTER: libgfapi based access to a Gluster Volume
- CEPH: libcephfs based access to the filesystem on a Ceph Cluster
Setting up a basic NFS-Ganesha server
Exporting a mounted filesystem is pretty simple. Unfortunately this failed for me when running with the standard nfs-ganesha packages on a minimal Fedora 20 installation. The following changes were needed to make NFS-Ganesha work for a basic export:
- install rpcbind and make the nfs-ganesha.service depend on it
- copy /etc/dbus-1/system.d/org.ganesha.nfsd.conf from the sources
- createa /etc/sysconfig/nfs-ganesha environment file
When these initial things have been taken care of, a configuration file needs to be created. The default configuration file mentioned in the environment file is /etc/ganesha.nfsd.conf. The sources of nfs-ganesha contain some examples, the vfs.confis quite usable as a starting point. After copying the example and modifying the paths to something more suitable, starting the NFS-server should work:
# systemctl start nfs-ganesha
In case something failed, there should be a note about it in /var/log/ganesha.log.
Exporting the Ceph filesystem with NFS-Ganesha
This assumes you have a working Ceph Cluster which includes several MON, OSD and one or more MDS daemons. The FSAL_CEPH from NFS-Ganesha uses libcephfs which seems to be the same as the ceph-fuse package for Fedora. the easiest way to make sure that the Ceph filesystem is functional, is to try and mount it with ceph-fuse.
The minimal requirements to get a Ceph client system to access the Ceph Cluster, seem to be a /etc/ceph/ceph.conf with a [global]section and a suitable keyring. Creating the ceph.conf on the Fedora system that was done the ceph-deploy:
$ ceph-deploy config push $NFS_SERVER
In my setup I scp‘d the /etc/ceph/ceph.client.admin.keyring from one of my Ceph servers to the $NFS_SERVER. There probably are better ways to create/distribute a keyring, but I’m new to Ceph and this worked sufficiently for my testing.
When the above configuration was done, it was possible to mount the Ceph filesystem on the Ceph client that is becoming the NFS-server. This command worked without issues:
# ceph-fuse /mnt
# echo 'Hello Ceph!' > /mnt/README
# umount /mntThe first write to the Ceph filesystem took a while. This is likely due to the initial work the MDS and OSD daemons need to do (like creating pools for the Ceph filesystem).
After confirming that the Ceph Cluster and Filesystem work, the configuration for NFS-Ganesha can just be taken from the sources and saved as /etc/ganesha.nfsd.conf. With this configuration, and restarting the nfs-ganesha.service, the NFS-export becomes available:
# showmount -e $NFS_SERVER
Export list for $NFS_SERVER:
/ (everyone)NFSv4 uses a ‘pseudo root’ as mentioned in the configuration file. This means that mounting the export over NFSv4 results in a virtual directory structure:
# mount -t nfs $NFS_SERVER:/ /mnt
# find /mnt
/mnt
/mnt/nfsv4
/mnt/nfsv4/pseudofs
/mnt/nfsv4/pseudofs/ceph
/mnt/nfsv4/pseudofs/ceph/READMEReading and writing to the mountpoint under /mnt/nfsv4/pseudofs/ceph works fine, as long as the usual permissions allow that. By default NFS-Ganesha enabled ‘root squashing’, so the ‘root’ user may not do a lot on the export. Disabling this security measure can be done by placing this option in the export section:
Squash = no_root_squash;
Restart the nfs-ganesha.service after modifying /etc/ganesha.nfsd.conf and writing files as ‘root’ should work too now.
Future Work
For me, this was a short “let’s try it out” while learning about Ceph. At the moment, I have no intention on working on the FSAL_CEPH for NFS-Ganesha. My main interest of this experiment with exporting a Ceph filesystem though NFS-Ganesha on a plain Fedora 20 installation, was to learn about usability of a new NFS-Ganesha configuration/deployment. In order to improve the user experience with NFS-Ganesha, I’ll try and fix some of the issues I run into. Progress can be followed in Bug 1144799.
In future, I will mainly use NFS-Ganesha for accessing Gluster Volumes. My colleague Soumya posted a nice explanation on how to download, build and run NFS-Ganesha with support for Gluster. We will be working on improving the out-of-the-box support in Fedora while stabilizing the FSAL_GLUSTER in the upstream NFS-Ganeasha project.
-
2014-09-10
GlusterFS RPMs for 3.4.6beta1 are available for testing
RPMs for 3.4.6beta1 are available for testing at http://download.gluster.org/pub/gluster/glusterfs/qa-releases/3.4.6beta1/ Above repo contains RPMs for CentOS 5, 6, 7 and Fedora 19, 20, 21, 22. Packages for other platforms/distributions will be available once they are build. If you find any issue … Continue reading →

-
2014-09-03
Introducing: Oh My Vagrant!
If you’re a reader of my code or of this blog, it’s no secret that I hack on a lot of puppet and vagrant. Recently I’ve fooled around with a bit of docker, too. I realized that the vagrant, environments … Continue reading →

-
2014-09-02
GlusterFS and NFS-Ganesha integration
Over the past few years, there was an enormous increase in the number of user-space filesystems being developed and deployed. But one of the common challenges which all those filesystems’ users had to face was that there was a huge performance hit when their filesystems were exported via kernel-NFS (well-known and widely used network protocol).To […]

-
2014-08-27
Rough data density calculations
Seagate has just publicly announced 8TB HDD’s in a 3.5″ form factor. I decided to do some rough calculations to understand the density a bit better… Note: I have decided to ignore the distinction between Terabytes (TB) and Tebibytes (TiB), since … Continue reading →

-
2014-08-21
User Story: Chitika Boosts Big Data with GlusterFS
Chitika Inc., an online advertising network based in Westborough, MA, sought to provide its data scientists with faster and simpler access to its massive store of ad impression data. The company managed to boost availability and broaden access to its data by swapping out HDFS for GlusterFS as the filesystem backend for its Hadoop deployment. …Read more
-
2014-08-13
Upgrade CentOS 6 to 7 with Upgrade Tools
I decided to try the upgrade process from EL 6 to 7 on the servers I used in my previous blog post “Windows (CIFS) fileshares using GlusterFS and CTDB for Highly available data” Following the instructions here I found the process fairly painless. However there were 1 or two little niggles which caused various issues which …read more
The post Upgrade CentOS 6 to 7 with Upgrade Tools appeared first on Jon Archer.
{kind=link}