-
2013-12-11
Gluster and (not) restarting brick processes upon updates
Gluster users have different opinions on when the Gluster daemons should be restarted. This seems to be a very common discussion for a lot daemons, and pops up on the Fedora Developers mailinglist regularly.An explanation on how and when Gluster starts…
-
2013-12-11
Gluster and (not) restarting brick processes upon updates
Gluster users have different opinions on when the Gluster daemons should be restarted. This seems to be a very common discussion for a lot daemons, and pops up on the Fedora Developers mailinglist regularly.An explanation on how and when Gluster starts…
-
2013-12-10
GlusterFS Keeps VFX Studio on the Cutting Edge
Cutting Edge, a visual effects company that’s worked on films such as The Great Gatsby and I, Frankenstein, had outgrown its NAS storage system and was in search of a way to boost its storage capacity and performance in the face of several large upcoming projects. The Australia-based firm turned to GlusterFS as an alternative …Read more
-
2013-12-09
Vagrant on Fedora with libvirt
Apparently lots of people are using Vagrant these days, so I figured I’d try it out. I wanted to get it working on Fedora, and without Virtualbox. This is an intro article on Vagrant, and what I’ve done. I did … Continue reading →

-
2013-12-05
It’s a GlusterFest Testing Weekend
If you’ve been keeping up with our weekly meetings and the 3.5 planning page, then you know that tomorrow, December 6, is the first testing “day” for 3.5. But since this is a Friday, we’re going to make the party last all weekend, through mid-day Monday. Here’s what you need to do: Take a look …Read more
-
2013-12-01
Using Gluster as Primary Storage in CoudStack
CloudStack could use a Gluster environment for different kind of storage types: Primary Storage: mount over the GlusterFS native client (FUSE)This post shows how it is working and refers to the patches that make this possible.Volumes for virtual machin…
-
2013-12-01
Using Gluster as Primary Storage in CoudStack
CloudStack could use a Gluster environment for different kind of storage types: Primary Storage: mount over the GlusterFS native client (FUSE)This post shows how it is working and refers to the patches that make this possible.Volumes for virtual machin…
-
2013-11-29
Do Open Source Communities Have a Social Responsibility?
This post continues my holiday detour into things not necessarily tech related. Forgive me this indulgence – there is at least one more post I’ll make in a similar vein. Open Source communities are different. At least, I’ve always felt that they are. Think of the term “community manager.” If you’re a community manager in …Read more
-
2013-11-27
Effective GlusterFs monitoring using hooks
Let us imagine we have a GlusterFs monitoring system which displays list of volumes and its state, to show the realtime status, monitoring app need to query the GlusterFs in regular interval to check volume status, new volumes etc. Assume if the polling interval is 5 seconds then monitoring app has to run
gluster volume infocommand ~17000 times a day!How about maintaining a state file in each node? which gets updated after every new GlusterFs event(create, delete, start, stop etc).
In this blog post I am trying to explain the possibility of creating state file and using it.
As of today GlusterFs provides following hooks, which we can use to update our state file.
create delete start stop add-brick remove-brick set
How to use hooks
GlusterFs hooks present in
/var/lib/glusterd/hooks/1directory. Following example shows sending message to all users usingwallcommand when any new GlusterFs volume is created.Create a shell script
/var/lib/glusterd/hooks/1/create/post/SNotify.bashand make it executable. Whenever a volume is created GlusterFs executes all the executable scripts present in respective hook directory(Glusterfs executes only the scripts which filename starting with ‘S’)#!/bin/bash VOL= ARGS=$(getopt -l "volname:" -name "" $@) eval set -- "$ARGS" while true; do case $1 in --volname) shift VOL=$1 ;; *) shift break ;; esac shift done wall "Gluster Volume Created: $VOL";
Experimental project – GlusterWeb
This experimental project maintains a sqlite database
/var/lib/glusterd/nodestate/glusternodestate.dbwhich gets updated after any GlusterFs event. For example if a GlusterFs volume is created then it updates volumes table and also bricks table.This project depends on glusterfs-tools so install both projects.
git clone https://github.com/aravindavk/glusterfs-tools.git cd glusterfs-tools sudo python setup.py install git clone https://github.com/aravindavk/glusterfs-web.git cd glusterfs-web sudo python setup.py install
By running setup, this tool will install all the hooks which are required for monitoring. (cleanup is for removing all the hooks)
sudo glusternodestate setup
All set! now run
glusterwebto start webapp.sudo glusterweb
Web application starts running in
http://localhost:8080you can change the port using--portor-poption.sudo glusterweb -p 9000
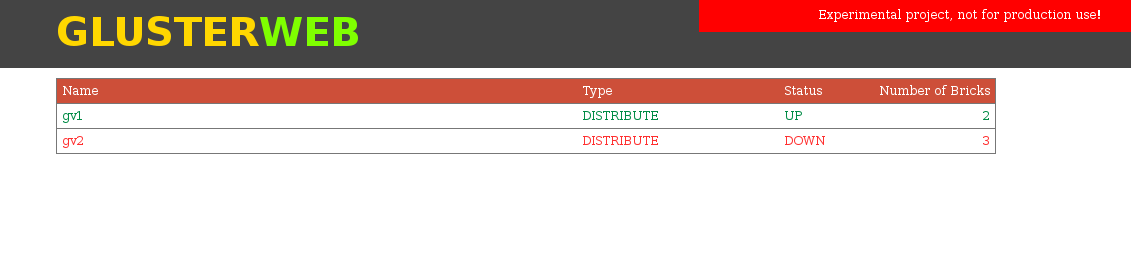
Initial version of web interface.
Future plans
Authentication: Option to provide username and password or access key while running glusterweb, For example
sudo glusterweb --username aravindavk --password somesecret # or sudo glusterweb --key secretonlyiknowMore gluster hooks support: we need more GlusterFs hooks for better monitoring(refer Problems below)
More GlusterFs features support: As a experiment UI only lists volumes, we need improved UI and support for different gluster features.
Actions support: Support for volume creation, adding/removing bricks etc.
REST api and SDK: Providing REST api for gluster operations.
Many more: Not yet planned 🙂
Problems
State file consistency: If glusterd goes down in the node then the database will have wrong details about node’s state. One workaround is to reset the database if glusterd is down using a cron job, when glusterd comes up, database will not gets updated and the database will have previous updated details. To prevent this we need a glusterfs hook for glusterd-start.
More hooks: As of today we don’t have hooks for volume down/up, brick down/up and other events. We need following hooks for effective monitoring glusterfs.(Add more if anything missing in the list)
glusterd-start peer probe peer detach volume-down volume-up brick-up brick-down
Let me know your thoughts! Thanks.
-
2013-11-27
It Was Never About Innovation
This is the first in a series of articles about innovation and open computing. Because it’s a holiday time of year in the USA, I’ve decided that these next few articles will be a detour from the usual stuff you’ll find here. Ever since a few of us got together to form the Open Cloud …Read more
-
2013-11-26
GlusterFS Block Device Translator
Block device translator Block device translator (BD xlator) is a new translator added to GlusterFS recently which provides block backend for GlusterFS. This replaces the existing bd_map translator in GlusterFS that provided similar but very limited functionality. GlusterFS expects the underlying brick to be formatted with a POSIX compatible file system. BD xlator changes that […]

-
2013-11-26
Advanced recursion and memoization in Puppet
As a follow-up to my original article on recursion in Puppet, and in my attempt to Push Puppet (to its limit), I’ll now attempt some more advanced recursion techniques in Puppet. In my original recursion example, the type does recurse, … Continue reading →

-
2013-11-26
A Gluster Block Interface – Performance and Configuration
This post shares some experiences I’ve had in simulating a block device in gluster. The block device is a file based image, which acts as the backend for the Linux SCSI target. The file resides in gluster, so enjoys gluster’s feature set. But the client only sees a block device. The Linux SCSI target presents …Read more
-
2013-11-25
Initial work on Gluster integration with CloudStack
Last week there was a CloudStack Conference at the Beurs van Belage in Amsterdam. I attended the first day and joined the Hackathon. Without any prior knowledge of CloudStack, I was asked by some of the Gluster community people to have a look at adding…
-
2013-11-25
Initial work on Gluster integration with CloudStack
Last week there was a CloudStack Conference at the Beurs van Belage in Amsterdam. I attended the first day and joined the Hackathon. Without any prior knowledge of CloudStack, I was asked by some of the Gluster community people to have a look at adding…
-
2013-11-20
Documentation for Puppet-Gluster
Ironically, one of the reasons that I started writing Puppet code, was so that I could spend more time designing and building, and less time writing documentation. I suppose I’m a victim of my success, because Puppet-Gluster has grown large … Continue reading →

-
2013-11-17
Iteration in Puppet
People often ask how to do iteration in Puppet. Most Puppet users have a background in imperative programming, and are already very familiar with for loops. Puppet is sometimes confusing at first, because it is actually (or technically, contains) a … Continue reading →

-
2013-11-15
Some Hive gotchas for non-production setups…
Setting up your IDE to test HIVE: Export hadoop environmental variables… Maybe some day it will be as easy to run hive fully locally as it is to run pig.FYI, this was just an initial post. For a deeper understanding of the real details of how h…
-
2013-11-14
First Impressions at AWS re:Invent
Last year I attended AWS re:Invent, kinda, sorta. We were in Las Vegas to put on the first Apache CloudStack conference and most of my time and brainpower were consumed with last-minute planning for that event. I did spend time in the developer area, on exhibit floor, and some of the after-parties – but it […]
-
2013-11-12
On the Gluster vs Ceph Benchmarks
If you’ve been following the Gluster and Ceph communities for any length of time, you know that we have similar visions for open software-defined storage and are becoming more competitive with each passing day. We have been rivals in a similar space for some time, but on friendly terms – and for a couple of …Read more