-
2013-12-01
Using Gluster as Primary Storage in CoudStack
CloudStack could use a Gluster environment for different kind of storage types: Primary Storage: mount over the GlusterFS native client (FUSE)This post shows how it is working and refers to the patches that make this possible.Volumes for virtual machin…
-
2013-12-01
Using Gluster as Primary Storage in CoudStack
CloudStack could use a Gluster environment for different kind of storage types: Primary Storage: mount over the GlusterFS native client (FUSE)This post shows how it is working and refers to the patches that make this possible.Volumes for virtual machin…
-
2013-11-29
Do Open Source Communities Have a Social Responsibility?
This post continues my holiday detour into things not necessarily tech related. Forgive me this indulgence – there is at least one more post I’ll make in a similar vein. Open Source communities are different. At least, I’ve always felt that they are. Think of the term “community manager.” If you’re a community manager in …Read more
-
2013-11-27
Effective GlusterFs monitoring using hooks
Let us imagine we have a GlusterFs monitoring system which displays list of volumes and its state, to show the realtime status, monitoring app need to query the GlusterFs in regular interval to check volume status, new volumes etc. Assume if the polling interval is 5 seconds then monitoring app has to run
gluster volume infocommand ~17000 times a day!How about maintaining a state file in each node? which gets updated after every new GlusterFs event(create, delete, start, stop etc).
In this blog post I am trying to explain the possibility of creating state file and using it.
As of today GlusterFs provides following hooks, which we can use to update our state file.
create delete start stop add-brick remove-brick set
How to use hooks
GlusterFs hooks present in
/var/lib/glusterd/hooks/1directory. Following example shows sending message to all users usingwallcommand when any new GlusterFs volume is created.Create a shell script
/var/lib/glusterd/hooks/1/create/post/SNotify.bashand make it executable. Whenever a volume is created GlusterFs executes all the executable scripts present in respective hook directory(Glusterfs executes only the scripts which filename starting with ‘S’)#!/bin/bash VOL= ARGS=$(getopt -l "volname:" -name "" $@) eval set -- "$ARGS" while true; do case $1 in --volname) shift VOL=$1 ;; *) shift break ;; esac shift done wall "Gluster Volume Created: $VOL";
Experimental project – GlusterWeb
This experimental project maintains a sqlite database
/var/lib/glusterd/nodestate/glusternodestate.dbwhich gets updated after any GlusterFs event. For example if a GlusterFs volume is created then it updates volumes table and also bricks table.This project depends on glusterfs-tools so install both projects.
git clone https://github.com/aravindavk/glusterfs-tools.git cd glusterfs-tools sudo python setup.py install git clone https://github.com/aravindavk/glusterfs-web.git cd glusterfs-web sudo python setup.py install
By running setup, this tool will install all the hooks which are required for monitoring. (cleanup is for removing all the hooks)
sudo glusternodestate setup
All set! now run
glusterwebto start webapp.sudo glusterweb
Web application starts running in
http://localhost:8080you can change the port using--portor-poption.sudo glusterweb -p 9000
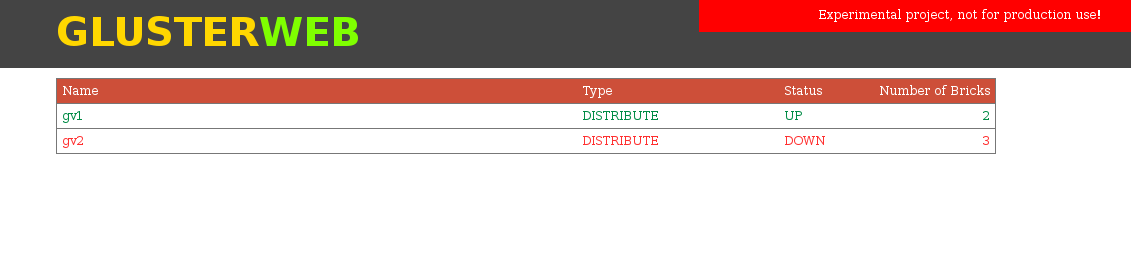
Initial version of web interface.
Future plans
Authentication: Option to provide username and password or access key while running glusterweb, For example
sudo glusterweb --username aravindavk --password somesecret # or sudo glusterweb --key secretonlyiknowMore gluster hooks support: we need more GlusterFs hooks for better monitoring(refer Problems below)
More GlusterFs features support: As a experiment UI only lists volumes, we need improved UI and support for different gluster features.
Actions support: Support for volume creation, adding/removing bricks etc.
REST api and SDK: Providing REST api for gluster operations.
Many more: Not yet planned 🙂
Problems
State file consistency: If glusterd goes down in the node then the database will have wrong details about node’s state. One workaround is to reset the database if glusterd is down using a cron job, when glusterd comes up, database will not gets updated and the database will have previous updated details. To prevent this we need a glusterfs hook for glusterd-start.
More hooks: As of today we don’t have hooks for volume down/up, brick down/up and other events. We need following hooks for effective monitoring glusterfs.(Add more if anything missing in the list)
glusterd-start peer probe peer detach volume-down volume-up brick-up brick-down
Let me know your thoughts! Thanks.
-
2013-11-27
It Was Never About Innovation
This is the first in a series of articles about innovation and open computing. Because it’s a holiday time of year in the USA, I’ve decided that these next few articles will be a detour from the usual stuff you’ll find here. Ever since a few of us got together to form the Open Cloud …Read more
-
2013-11-26
GlusterFS Block Device Translator
Block device translator Block device translator (BD xlator) is a new translator added to GlusterFS recently which provides block backend for GlusterFS. This replaces the existing bd_map translator in GlusterFS that provided similar but very limited functionality. GlusterFS expects the underlying brick to be formatted with a POSIX compatible file system. BD xlator changes that […]

-
2013-11-26
Advanced recursion and memoization in Puppet
As a follow-up to my original article on recursion in Puppet, and in my attempt to Push Puppet (to its limit), I’ll now attempt some more advanced recursion techniques in Puppet. In my original recursion example, the type does recurse, … Continue reading →

-
2013-11-26
A Gluster Block Interface – Performance and Configuration
This post shares some experiences I’ve had in simulating a block device in gluster. The block device is a file based image, which acts as the backend for the Linux SCSI target. The file resides in gluster, so enjoys gluster’s feature set. But the client only sees a block device. The Linux SCSI target presents …Read more
-
2013-11-25
Initial work on Gluster integration with CloudStack
Last week there was a CloudStack Conference at the Beurs van Belage in Amsterdam. I attended the first day and joined the Hackathon. Without any prior knowledge of CloudStack, I was asked by some of the Gluster community people to have a look at adding…
-
2013-11-25
Initial work on Gluster integration with CloudStack
Last week there was a CloudStack Conference at the Beurs van Belage in Amsterdam. I attended the first day and joined the Hackathon. Without any prior knowledge of CloudStack, I was asked by some of the Gluster community people to have a look at adding…
-
2013-11-20
Documentation for Puppet-Gluster
Ironically, one of the reasons that I started writing Puppet code, was so that I could spend more time designing and building, and less time writing documentation. I suppose I’m a victim of my success, because Puppet-Gluster has grown large … Continue reading →

-
2013-11-17
Iteration in Puppet
People often ask how to do iteration in Puppet. Most Puppet users have a background in imperative programming, and are already very familiar with for loops. Puppet is sometimes confusing at first, because it is actually (or technically, contains) a … Continue reading →

-
2013-11-15
Some Hive gotchas for non-production setups…
Setting up your IDE to test HIVE: Export hadoop environmental variables… Maybe some day it will be as easy to run hive fully locally as it is to run pig.FYI, this was just an initial post. For a deeper understanding of the real details of how h…
-
2013-11-14
First Impressions at AWS re:Invent
Last year I attended AWS re:Invent, kinda, sorta. We were in Las Vegas to put on the first Apache CloudStack conference and most of my time and brainpower were consumed with last-minute planning for that event. I did spend time in the developer area, on exhibit floor, and some of the after-parties – but it […]
-
2013-11-12
On the Gluster vs Ceph Benchmarks
If you’ve been following the Gluster and Ceph communities for any length of time, you know that we have similar visions for open software-defined storage and are becoming more competitive with each passing day. We have been rivals in a similar space for some time, but on friendly terms – and for a couple of …Read more
-
2013-11-06
Cutting in the Middleman, with Comments
I blogged somewhat recently about my interest in, and inaction around, static site blogging, where you write blog posts, use an app to turn them into plain HTML, and then drop them somewhere on the web, with no shadow of potentially/eventually vulnerable PHP and MySQL cranking away to deliver dynamically what needn’t be dynamic.
I hadn’t yet pulled the trigger on ditching WordPress yet, preferring instead to satisfy my desire for writing posts in plain AsciiDoc-formatted text by copying and pasting rendered AsciiDoc into WordPress, or using this AsciiDoc-to-WordPress script to pump in posts through the WordPress API.
Mainly, what I was missing was for one of my bad ass colleagues to take the crazy box of lego pieces that get dumped out in front of your feet when you ask Google about static site blogging, make some smart choices, and build something that I could come along and tinker with. I mentioned before that I messed around with Awestruct and found it way too raw for me. After their own more able-minded examination, my colleagues agreed, and came forward with Middleman.
Middleman It Is, But…
After poking a bit through Middleman, I felt comfy enough to adapt it for my own, extremely simple blog. I got a basic layout in place, and set about converting my WordPress posts into something workable for Middleman. My plan was to use AsciiDoc for my new writing, but most conversion scripts target the more popular Markdown. I found a script — I’ll look for the link — that did an OK job converting, but I had to delete some of the “front matter” bits that I didn’t need, and a few of my URLs rendered wrong. I’ve tried a few different tools for WordPress-to-SomethingStatic conversion, and they’ve all needed some hand-tweaking. So, low-frequency blogging FTW! I didn’t have too many posts to hand-tweak.
Now on to a REAL problem — comments. One arguably important dynamic chore tackled by WordPress is accepting and managing blog comments. Most static blogs either do away with comments all together (easy to steel yourself for this decision after reading comments at Youtube or your local newspaper’s web site for five minutes) or, sites go with the hosted Disqus comments service.
I’ve bounced between Disqus and WordPress comments in the past, and have been happy with Disqus. They take the load off your site, and allow your page (with the help of something like wp super cache) to be mostly static, since all the dynamism happens, in javascript, in your reader’s browser. Also, I like the way that Disqus knits siloed discussions from all over the web into something a bit more unified. You have posts and comment threads spread everywhere, and Disqus sort of pulls them together, and, through easy options for tweeting out a link to your comment, offers a way to pull in others.
Switching from WordPress comments to Disqus comments means switching from a possibly self-hosted system to a definitely not self-hosted system, and that’s a concern for many, particularly given the greater chances for privacy chicanery at sites out of your control. However, Disqus does a really good job importing from and exporting to WordPress, so even though I’ve swapped back and forth a few times, I’ve never had trouble getting my mitts back on my data, and that’s my number one concern with using a hosted service.
BUT, there’s still another important issue. WordPress is open source software, and Disqus is not. I’m big on open source software — I’m not opposed to using anything proprietary, not sure how I’d use my oven with a no-proprietary-ever stance, but I’m keen to see open source spread, so swapping something that’s already open to something that is not is a concern.
Enter Juvia, and OpenShift (natch)
As usual, I approached the oracle of Google and, in fairly short order, was directed to Juvia, “a commenting server similar to Disqus and IntenseDebate.” It sounded perfect, and not completely abandoned, although the demo site wasn’t working, and its discussion forum (served from the terrible terrible why-does-anyone-use-this Google Groups) appears to have been wiped from the earth. Why not more activity around what appears to be a much-needed project?
It may be because Juvia is a Ruby on Rails app, and while mysql/php hosting is handed down from the sky at little or no cost, ruby hosting is not. I saw one discussion of Juvia v. Disqus in my travels that boiled down to: “You could use Juvia, but hosting costs, so, use Disqus, which is free.”
But, that gentleman mustn’t have been aware of OpenShift, where you can host all sorts of different apps in the service’s free tier. I turned again to Google and found a few Juvia on OpenShift quickstarts. I used this one, altough this one seems more official, though a bit less up-to-date.
I spun up Juvia in one of my OpenShift gears, spun up another just to host my static blog files, and poked at my layout HAML until I got them working together. I used Juvia’s WordPress comments importer to import my WordPress comments (which took some work), and here I am.
Now, I am going to write all this up into a how to, but I need to do a bit more polishing — you don’t want to follow the steps I followed, you want to follow the steps I would have followed, had future me paid me a visit first.
Till then, though, this is my first new, non-stub post in the new blog. With open source, self-hosted comments.
-
2013-11-05
Pushing Puppet at Puppet Camp DC, LISA 2013
Hi there, I hope you enjoyed my “Pushing Puppet (to its limit)” talk and demos from Puppet Camp D.C., LISA 2013. As requested, I’ve posted the code and slides. Here is the code: https://github.com/purpleidea/puppet-pushing This module will require three modules … Continue reading →

-
2013-11-05
Special Report: Scale Out with GlusterFS
Learn how to install, benchmark and optimize this popular, shared-nothing and scalable open-source distributed filesystem in this special 12 page report.
Please provide your email below for …
-
2013-11-05
Recap of Gluster Community Day at USENIX LISA
 Yesterday we had the opportunity to run a Gluster Community Day at USENIX LISA in Washington D.C. Turns out it was well worth the time, as we had a fantastic group turn up for some really excellent talks.
Yesterday we had the opportunity to run a Gluster Community Day at USENIX LISA in Washington D.C. Turns out it was well worth the time, as we had a fantastic group turn up for some really excellent talks.The crowd wasn’t large, but it was clearly a group that was interested in GlusterFS and associated projects, like puppet-gluster. Having the right crowd is almost always better than having a big, but disinterested, crowd.
Planned to write up a post to summarize the event, but it looks like James Shubin has beaten me to the punch with a fantastic post on The Technical Blog of James. Be sure to check out James’ post, and if you’re interested in Gluster, Puppet, and other technical goodness, put his blog’s feed in your favorite reader. (He’s also on Twitter as @purpleidea.)
Many thanks to the attendees for turning up, and to Wesley Duffee-Braun, Eco Willson, and James for giving some fantastic talks and Gluster wisdom.
Don’t forget, we also have a Gluster Birds of a Feather (BoF) here at LISA on Thursday. Join us at 8:00 p.m. in the “Hoover” room.
-
2013-11-05
What Every Admin Should Know About Email
Email is a fantastic tool, when used correctly. It almost never is. Rikki Endsley asked me if I’d like to write something for USENIX ;login; logout, and it happened to be right after processing a slew of terrible email: people sending two-line replies at the end of several hundred lines of text, inexcusable top-posting, HTML-ized […]