The k/v pair salmon run in mapreduce -> hdfs.
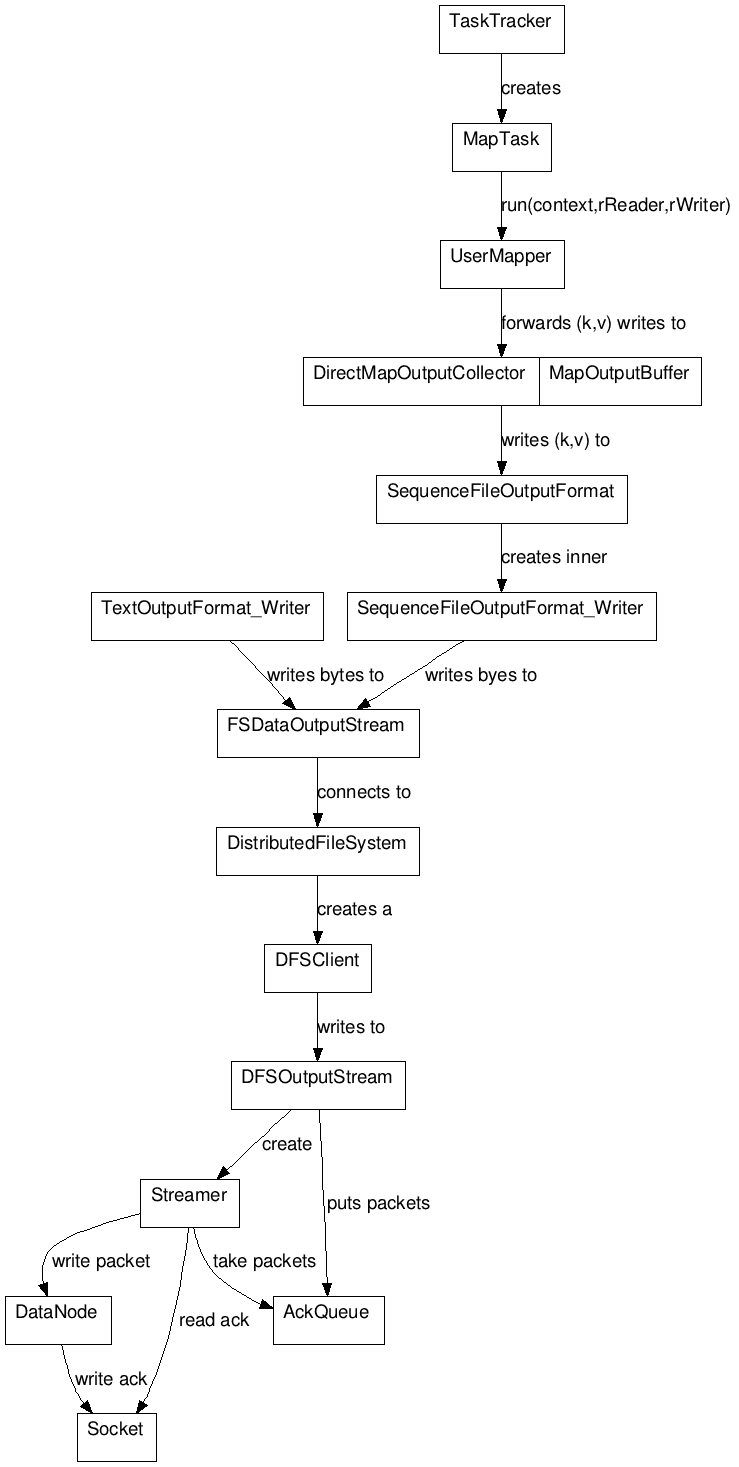 |
| The HDFS write path is lonnnng and hairy. Here’s some imagery of it (somewhat raw and undervalidated, so please comment if something looks funny). |
Have you ever seen those little salmons that swim ALL THE WAY up the river, into the ocean, just to breed? Well thats kinda how k/v pairs in MapReduce applications work. They have to go a LONG WAY before the finally get to reside somewhere permanently on local disk.
The fact that MapReduce abstracts “key/value” pairs as an application level nicety makes the write path for a real file very intriguing.
First off – MapReduce distributes your k/v pairs into partitions:
- For a given MapReduce job, you typically have several output files. These are called partitions (part-r-0000, part-r-0001, …).
- Each file in HDFS is broken into BLOCKS.
- The partitions are requested by the MapReduce layer – every time a mapper runs, a “part-****” file output stream is created. This is done by the FileOutputFormat classes.
- The first “level” of buffering that you control is in the FileOutputFormat – which takes k,v pairs directly. Although TextOutputFormat doesn’t seem to buffer, other output formats (SequenceFileOutputFormat), actually do.
Note : Partitions are a user-level feature – is the fundamental mechanism for distributing algorithms over a cluster. Since each partition corresponds to a single reducer, you need to be careful that you partition your workloads evenly – otherwise you’ll get the “long-tail” problem (example: a web crawler with keys as domain roots with default partitioning will be extremely inefficient – because the most common sights will only be crawled in a single reducer).
Next: The partition files are broken into blocks, and written to the DFS:
- Buffering of writes occurs inside of the DataStreamer, which creates a “blockStream” for writing.
- The main job of the DFSOutputStream class is to translate bytes into packets that can be written and acknowledge reliably.
- The DFSOutputStream uses its inner DataStreamer class to handle the logic of creating OutputStreams which directly write to, and acknowledge progress, of writing contents to a block.
- Writing to the DFSOutputStream is fast – no waiting on remote calls synchronously. All acks are aynchronously done (if youre reading this post, though, you probably alredy know that).
- The DataStreamer picks the packets up off the ackQueue, and once a packet is the “last” one in a block, the block is closed for writing, and a new one is created.
There are thus at least two layers of client side buffering that occur in HDFS – one, the buffering of the output stream which is directly writing over a socket to remote blocks, and two, the buffering which occurs as a natural consequence of the fact that “Packets” accumulate a certain amount of bytes in memory before they are put on the write queue.
Inspect the k/v salmon-run write path for yourself :
There could be some ambigueties or (gasp) inaccuracies in the diagram above. Please do feel free to validate it and comment. The class names correspond directly to those used in the nodes of this graph. The github urls for the corresponding hadoop projects are :
- https://github.com/apache/hadoop-common
- https://github.com/apache/hadoop-hdfs
- https://github.com/apache/hadoop-mapred
Of course, it would behoov you to scour this code using eclipse, since there are 100s of relevant classes, and you can easily build eclipse projects from the sub projects by running “mvn eclipse:eclipse”.
You might also want to run the full build. In order to do that you’ll have to have protobuffs installed : http://stackoverflow.com/questions/15745010/org-apache-maven-plugin-mojoexecutionexception-protoc-failure.
Generating the graph :
This graph can be generated in graphviz using the neato layout, or on erdos http://sandbox.kidstrythisathome.com/erdos/, which can visualize reasonably sized graphviz snippets.
digraph g{
node [shape=record];
MapOoutputCollector [label=”<f1> DirectMapOutputCollector|<f2> MapOutputBuffer”];
DFSClient -> DFSOutputStream [label=”writes to”];
DFSOutputStream -> Streamer [label=”create”] ;
DFSOutputStream -> AckQueue [label=” puts packets”];
Streamer -> AckQueue [label=”take packets”];
Streamer -> DataNode [label=”write packet”] ;
Streamer -> Socket [label=”read ack”] ;
DataNode -> Socket [label=”write ack”];
DistributedFileSystem -> DFSClient [label=”creates a”];
TaskTracker -> MapTask [label=”creates”];
MapTask -> UserMapper [label=”run(context,rReader,rWriter)”];
UserMapper -> MapOoutputCollector [label=”forwards (k,v) writes to”];
MapOoutputCollector -> SequenceFileOutputFormat [label=”writes (k,v) to”];
SequenceFileOutputFormat -> SequenceFileOutputFormat_Writer [label=”creates inner”];
SequenceFileOutputFormat_Writer -> FSDataOutputStream [label=”writes byes to”];
TextOutputFormat_Writer -> FSDataOutputStream [label=”writes bytes to”] ;
FSDataOutputStream -> DistributedFileSystem [label=”connects to “];}