Set up a spark application development environment in Fedora
You want to learn scala. And you want to learn spark. And you’ve heard of SBT. Where do you start?
There are alot of different idioms for developing spark apps. One possibility is to use Ipython and Pyspark, which I’ve written up about a week ago.
Another – idea ? User IDEA.
IntelliJ offers a glorious spark editor and environment, which appears to be more well integrated and fault tolerant than the eclipse scala-ide plugin, at first glance.
 |
| Download intelliJ and extract it to /opt/ make sure you open permissions on it. |
Here’s how to get started.
First install IntelliJ from the tarball. Then extract it to /opt/. And start it like this:
| I start IntelliJ in linux by calling the shell script like this ^^. | Dont run this as root ! |
Next. Choose Not to import existing settings, accept licensing, Install some minimal VCS plugins (git), and click through… I like to install
- Git
- IDETalk
- Groovy
- Github
- Console/Terminal
Most of the stuff isn’t super useful for bigdata, so dont be afraid to deselect almost everything.
 |
| Go strait to Configure. Do not pass GO. Do not collect 200$. |
Now that you have a IntelliJ Evnironment set up, lets add SBT. To do this, click on Configure -> Browse Repositories. Then, in the diagram below, by typing SBT, you will see that there is an SBT Plugin. Click install. Then, install the Scala plugin also.
 |
| Install the 3 main Scala plugins, then restart |
Now you can restart IntelliJ… Go ahead and create a new project. You should see an option for SBT, choose it.
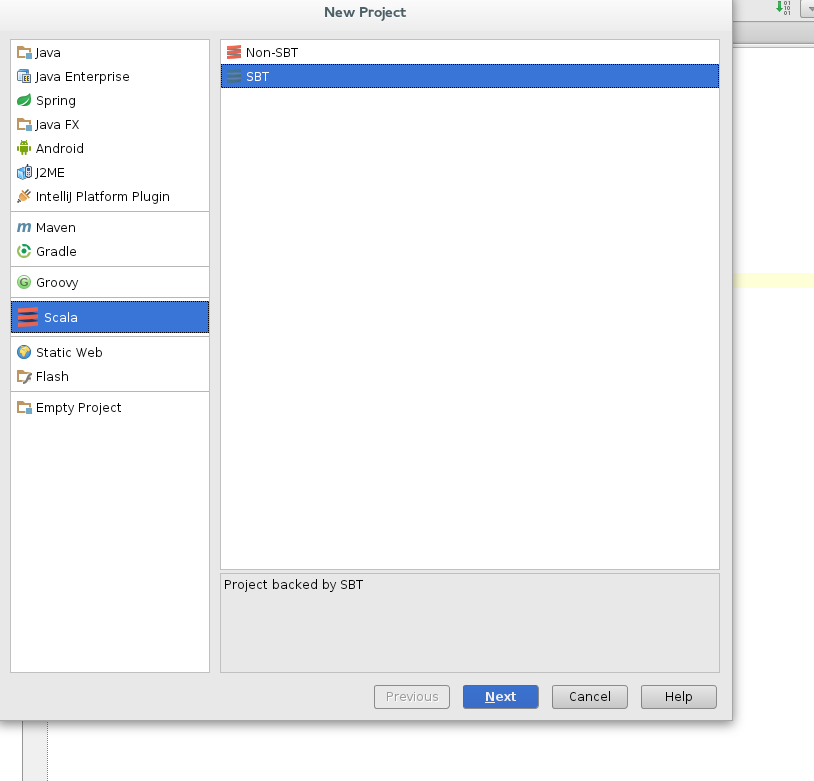 |
| Although we create a new project, we will point it to the existing blueprint app as you will see in the next step. IntelliJ will build the IDE specific stuff for us on top of our core code base. |
Then ,
1) FORK this project https://github.com/jayunit100/SparkBlueprint.git on github and
2) CLONE your fork (i.e. git clone git@github.com:jayunit100/SparkBlueprint.git )
Now, when you click NEXT in the box above, select the directory of the blueprint application.
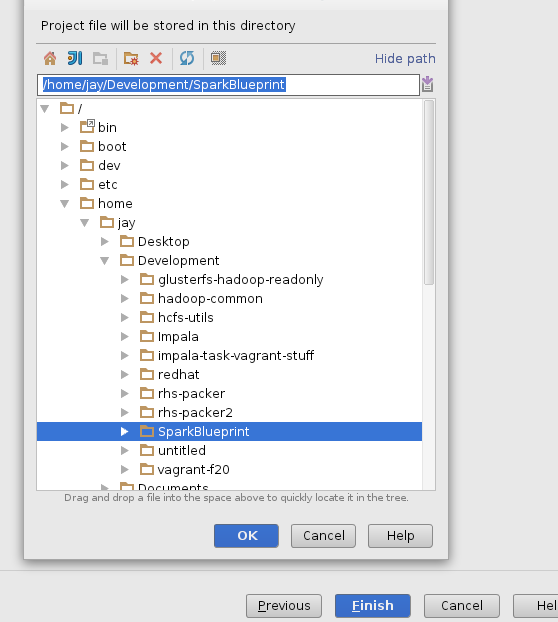 |
| Import the pre existing spark blueprint app. |
Okay ! Now give it some time. Your IDE will be indexing and downloading scala / spark jars for a while. You can see it happening in the bottom pane.
 |
| It takes a while to download all the jars in the beggining. |
Now, before you can properly run anything, you will want to set the JDK in your project structure. Go to File->Project Settings -> Project Structure -> Project JDK and select the version of open JDK you have (1.7+ should work) installed.
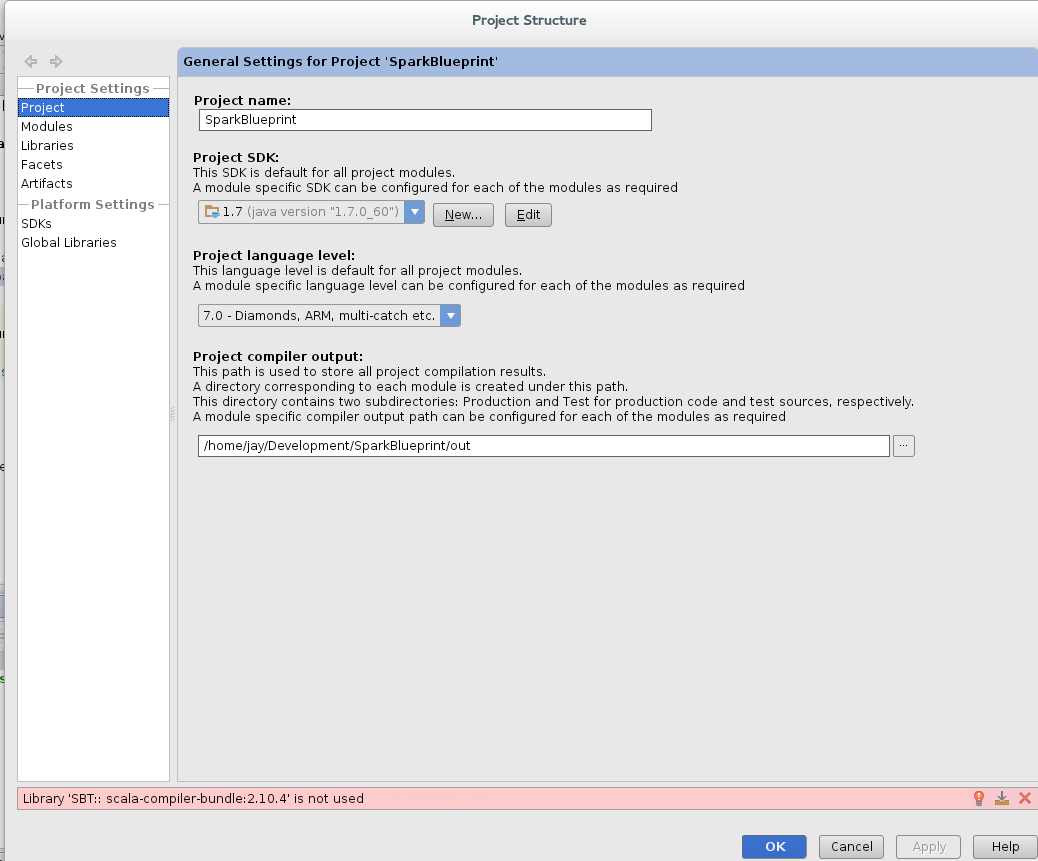 |
| This is critical : Set up your JDK in the Project Structure view. |
Now, run a spark job ! This is pretty easy. Just right click on the project at the upper left hand pannel and click “Run all tests”. You can see that there is a single class in this repo that has a test which simply launches a spark job.
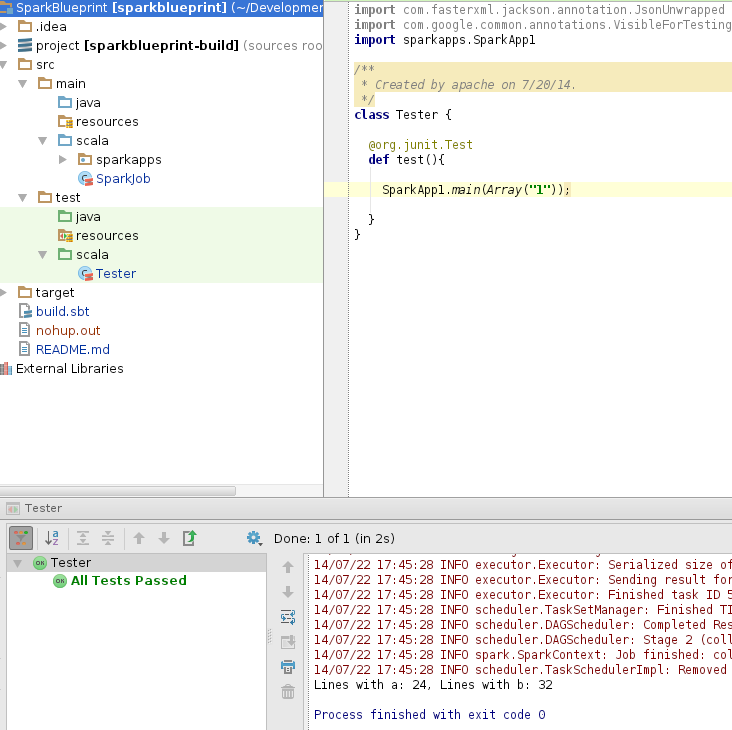 |
| At the bottom you can see our spark job succeeded. |
This is a bare bones, minimal implementation of a spark app. Over time, I’ll add more to it and it should be increasingly usable.
For those who don’t like ides, you can always use sbt alone to do the same thing.
sbt compile.
When you are ready to build a new jar for your spark cluster, you can do
sbt package
And you will see your jar file is output for you.
thats all for now!!!