Envelope-driven development
This post is about parsimonious planning, back-of-the-envelope engineering, and extreme productivity.
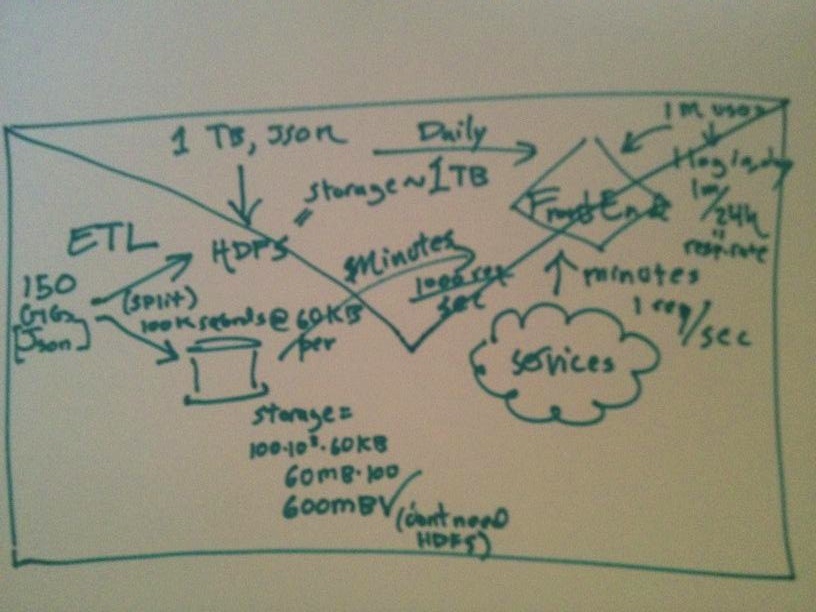 |
| By back of the envelope, we don’t mean flow charting. Rather, we mean real world consideration of the quantitative aspects of all of the major segments in a system. Notice that there is little mention of accidental aspects of the system (i.e. Java, C++, AWS, Java, Heroku, …). The envelope doesn’t document technology – rather, it tells us about the actual problem we are solving in a largely technology independent manner. |
This post is not about brain teasers: Rather, its about spurring your ability to implement envelope-driven-development in the real world, quickly.
I’m not a hardware guy, not at all. But in any case, I’m going to (attempt to) show you how to quickly walk through 3 simple estimation problems which test your ability to estimate the necessary CPU, I/O, etc… resources for maintaining a simple web site. Of course, the example site can’t be too simple – otherwise, we wouldn’t learn anything. So… we’ll use a “community forum” as the template (i.e. the website is dynamic, and grows over time).
But first, especially if you’re new to this: to get better at back-of-the-envelope calculations – I suggest spending some time on these websites:
- mothereff.in/byte-counter (A simple and easy get a feel for data size for single records).
- http://infolab.stanford.edu/~backrub/google.html (the original plan, from the 1990s… the definitive back of the envelope use case, because google still hasn’t solve this problem)
- http://aws.amazon.com/whitepapers/ (great case studies here, to get your mind ready)
- http://www.t1shopper.com/tools/calculate/ (numbers!)
- http://architects.dzone.com/articles/every-programmer-should-know (more numbers)
- http://www.hypexr.org/ (great for linux tricks for estimating file sizes, copying files, etc..)
Prototypes vs Envelopes
Before we begin, lets consider the benefits of envelope-driven development in light of the infamous “prototype”. We’ve all built a prototype before, and we have probably learned that prototypes don’t always tell us very much about the way our real world application will scale. In addition, they take a while, and involve alot of boilerplate coding that doesn’t advance our intuition about the target system we’re trying to build.
| Estimate | Prototype | |
| Data Scale | TB of data and beyond | MB of data |
| Time | Days or less | Weeks, Months |
| Deliverables | Scalability estimates, hot spots for further research. Quantitative metrics for moving forward. | “Working” code (grain of salt!) that usually doesn’t really work at all. |
| Cost($) | 100s-1000s | 1000s (novice built), 10K-50K+ (expert built) |
So there you have it: Our back of the envelope architecture deals with large data sets (by abstracting them), in a shorter period of time, without overpromising. The only real advantage to building a prototype as a first go is if you really, really, really must see working code for some reason (i.e. you are evaluating the competency of the people building your system, rather than focusing on the system itself). It this is the case – this article is not for you. This post is for those who know, from the get-go, that the system they are building is of primary importance, having direct, immediate value… So, here’s how this is gonna work:
- These exercises aren’t knowledge based! Novices should be able to attempt them.
- Each exercise will begin with some basic facts, which you might need to answer the question.
- The questions will be highlighted in green, for the impatient.
- None of these questions are particularly difficult. But… If you aren’t used to thinking in terms of real, hard numbers for software deployments, they might throw you off a little.
- The “scenario” here is as follows: You’re architecting the deployment for a web-forum, which will need to respond to a reasonable number of requests, grow over time, and feature a search functionality – and you want to know what, if any, bottlenecks you might run into from an i/o, disk usage, server bandwidth perspective.
Exercise 1
- The average packet size is 1 KB.
- There is 1 char per byte in UTF 8 (duh)
- This bullet has under 60 UTF8 bytes in it… precisely: 50.
- There are 1000KB in a megabyte (duh).
- 10E6 = 1 Million. 10E6 bytes = 1 MB
Now: lets say you are building a web-forum, you know, like http://www.skateboard-city.com/ or something… And you want to estimate how big your database might need to get, and its growth rate (so that you can decide where to host it, what scalability issues you might have, etc).
Assuming, say 1000 users, with 10 posts a day… What kind of computing infrastructure do you need to manage the data ?
We can easily simplify the question by bounding this question, by again being parsimonious… Lets just put a cap of 100GB on the amount of disk space. It makes the problem extremely tractable. We know that any modern hard drive can easily handle that.
So the question now becomes: will your forum-thingy ever exceed 100GB of data?
If not, clearly, its data can be contained a small linux box under your desk. Armed with nothing other than the above data points, we can safely (and confidently) determine a back-of-the-envelope answer to this question : with no coding required.
Assumption: Lets assume that a typical forum post might be a paragraph ~ thats about 4 sentences. Okay… So how much data is that?
Your growth rate is about 240 bytes per day, times 10, which amounts to about 2.4 kilo bytes per day, which is about 3/1000 Megabytes. So, it will take you a year to hit the MB mark, and 1000 years to reach the gigabyte mark. Which means that you can save your entire forum on a a tiny hardrive, or even, a USB thumb drive, for years to come (we can safely assume that you also have space to save the basic static content of the site, as well, which won’t be growing).
The answer: The 100GB limit won’t be reached for quite some time. Your safe hosting this on a rinky-dink machine that sits underneath your desktop. At least, your safe in terms of disk space.
Now, lets focus on scaling this burgeoning forum so that continues to be responsive under expected load.
Okay : So the last question was pretty easy. 10 posts a day isn’t that much. We know that we can host our fictional forum’s core database, which grows reasonably slowly, on a cheap box under our desktop. But, can we handle the traffic, i.e., the i/o ?
Now, again, here are the freebies:
- You know you can stream music on your computer.
- A typical song is 3MB, and you only listen to pop (~3 minutes)
- You can upload and send an image using wifi from your iphone in 10 seconds.
- A typical image is 1MB.
- The amount of time it takes to send a packet (1.5 KB or so) around the world is about 100 milliseconds.
What is the cost (in terms of bandwidth), for hosting 10,000 hits ? First, lets assume that each page will have 2.4 KB of content. But… since we know that the data on our site will be an underestimate of a page’s size, we might want to bump that up to 10KB, per page, just to be safe.
Is that a good estimate?
We can easily find out by firing up the terminal and checking:
find ./ -name *html | xargs ls -altrh
Again, we’ve just “sureyed” a reasonably sized sample of html pages with no “real” coding required.
On my laptop, most of the HTML files are, in fact, between 10 and 50 KB. So… Lets bump it up another order of magnitude, just to be safe. We will estimate that our forum page sizes are 100KB a pop.
So, spreading 100KB over a period of 24 hours (admittedly, ignoring peak times), we need an upstream connection speed of 10,000*100KB/24 hours = 50,000 KB/ hour = 50 MB / hr.
Okay, so we need to stream around 50MB per hour. Can we easily do this on a small machine on a reasonably fast, conventional network?
Again, we can simplify this by being pessimistic: can our home internet connection handle that sort of load ? Easily. Without googleing for “Megabytes per hour, home internet”, we can estimate this as well. Since our Iphone is capable of uploading 1 MB in under a minute, its obvious that we can handle 60MB in under an hour. Problem solved.
Exersize 3
Lets say we want to enable a search engine for our little blog site. How much extra disk space would we need to index all the text on the site, and how will we host the site?
This one is trickier because we need to factor in CPU cycles, Memory, and the architecture of a search engine. Here’s a really aweomse freebie for this exersize that you can tuck away:
- The initial google whitepaper’s lexicon of all words spanned 14 million words.
A quick reality check : So: Let’s estimate how much memory this might take up: if each word is ~8 characters, at 8 bytes/character, we have about 64 bytes per word. 64 bytes/word * 10 million words ~ 640 million bytes, which is around 640 MB. The actual size of the first google search engines word index was around 256MB, which means they might have used some sort of compression to store the words… OR, that the average word length is less than 8 characters. A quick google search yields 5.10 as the average word length. What happens if we plug this into our estimate? We get slightly closer ~400 MB. So… maybe words on the web are smaller. We’re certainly close enough for this estimate, and its encouraging that, by adding more data to our equation, we get almost 50% closer to the “right” answer.
And, finally, here are the other basic ingredients that we will need to drum up a badass estimate for our now fictional, searchable forum:
- Search engines use “inverted indexes” : i.e., they dont index each page separately with terms, because this would mean that a search would have to traverse ALL pages. Rather, they index words that point to documents, and use a hashing function to find the exact location of a word in constant time.
- The average home computer has about 4G of RAM.
Finally! The question:
Do we need to buy extra RAM or buy a multi-core machine CPU to host a performant search-engine for forum ?
Again, we start by translating the question: Will our search engine be CPU/Memory intensive? More specifically… Will our intel quad-core chip and 4GB machine be able to handle the load (lets assume 2GB is reserved for other applications, which means the server is effectively 2GB).
First, we can tackle the CPU cycles :
- We know these will not be an issue because looking up an inverted index is a constant time operation.
- We also know that if our server is under sever load, there will be alot of CPU cycles spent processing requests which may decrease its availability for searches.
Another aside, just to be safe – lets estimate the amount of free CPU time which we expect to have for searching: To estimate if CPU load is going to be effected by incoming requests, we have: 10,000 (number of requests daily) / 24 (hour) ~ 50 req/hr. Assuming our web servers can handle one request in under 100 ms, this means that they, on average, will be spinning over requests for 5000ms, per hour, which is 6 seconds, or 1/600th of an hour, which means there should be more than enough CPU bandwidth to go around.
And as far as memory is concerned, that’s easy to 🙂
- We can guess that our site will certainly have an in-memory word index of below 500MB, since Google’s initial search index, which spanned tens of millions of pages, was only 250MB.
- So, again…. it looks like our tiny linux box will be capable of hosting an internal search engine and index, entirely locally. Yay 🙂
So… what have we learned from our little envelope friend ?
- The disk space won’t exceed a few hundred Gigs for a few centuries, assuming that we don’t grow too fast. So no need for any fancy remote hard disk cloud stuff, at least not for storing content.
- The web server will be streaming 50MB or so an hour, which is reasonable and easy to maintain.
- The search engine just needs a few 100 extra MB or ram to do its job… no problem!
- With a little DIY and some creative thinking, its pretty clear that this forum can be done with extreme parsimony !
Final Thoughts
Thanks google!
I had to practice this stuff for the dreaded google-interview once. Thats how I got started down this masochistic road. I didn’t get the job, I think because of the fact that I was struggling to find a recursive solution to the gray code problem… Or something like that… But I learned ton about on the fly estimating when preparing for it, and I got to eat ice cream out of some kind of robot-ice-cream-truck thingy, while witnessing my brain ooze out of the sides of my ears. So I think it was a worthwhile experience.
But oddly enough: they never really even asked me any estimation questions.
I think estimation questions aren’t particularly popular at a lot of software companies… I can’t, for the life of me, imagine why. It seems like estimation is the single most important aspect of our day to day lives as developers. I think this might be because most programmers secretly hate non-discretized (i.e. continuous) functions, which tend to be really important when doing back-of-the-envelope calculations. Or maybe most programmers just don’t like envelopes? Or maybe we, as developers, just like building new stuff so damn much that we would rather do extra work than be parsimonious about executing things efficiently. In any case, even if you like doing extra work… You can still benefit from parsimony: It frees you up to work on truly interesting problems, by decreasing the amount of time that you waste spinning your wheels on lukewarm, prototypical, not-quite-there-yet code.
Now its your turn!!!!!!!!!!!!!!!!!!!!!
Now that you’ve been conviced that back-of-the-envelope engineering is awesome, fun, and valuable, I’m sure you’re wondering: Where can I find more problems? Harder ones? How can I become an expert in this stuff?
Well… when I was in grad school, I remember a guy named Marty Schiller – he was a protein bioinformatician who did real experiments on real cells… and he used to back-of-the-envelope every experiment we did. Why? Because real experiments cost money, and his wife always wanted him to be home on time. He was a parsimonious bastard! And he got good at parsimony by applying it, every day, to his own work.
So… Want to be an envelope expert? Be like marty : Just take 20 minutes every morning to estimate the amount of CPU, memory, and disk I/O resources that your days work will be using. You can even do this if your not an engineer : just use rough benchmarks, i.e., assume that actively browsing the web takes up 3% of the memory on your computer, and that watching a YouTube video consumes 15% of your network download bandwidth, etc… Or better yet, use htop, along with your task manager, to actually see what kind of resources you use for common tasks.
The fringe benefits of this sort of thinking are reaped immediately. You’ll be amazed at the effects this have on your work. You will suddenly understand concurrency, non-blocking IO, database internals, and the underlying functionality of your platform much better, without ever having to buy a book about them. Why? Because when you start back-of-the-enveloping, you force yourself to understand the fundamentals of the system you are dealing with.
One last, final warning:
Don’t let your back of the envelope estimate turn into an executive summary. Really… if the envelope could predict the size of the human genome, convey the architecture of the worlds first laser light generator, and predict the magnitude of the first nuclear explosion (yes, in fact, these are 3 famous, landmark envelope predictions which were all within an order of magnitude) – its probably quite capable of describing the meat of your current software-architecture, regardless of the accidental complexities technolog(ies) involved.