Deep dive into Hadoop with Bigtop and Eclipse Remote Debuggers
Thanks to a little hack session with bradley childs over at Red Hat this week, I learned a new trick: Remote debugging of JVM (Hadoop + MR2) apps in eclipse.
This post summarizes that trick… which has has been derived from other work online, such as this excellent post on the same topic.
 |
| Mirroring source code in eclipse and using the remote debugger with your java runtime in a VM allows you to, via the agentlib, inject byte code at runtime into running jvm processes which allow you to step through, line by line, the trickiest parts of your app – which is running in your production servers. |
In particular, this example will use hadoop (MR2) – but it should work with any JVM app which you have:
– A machine with a Java debugger tool implementing the JDPA.
– A secure connection to the machine running the binary.
– A working understanding of the eclipse debugger and breakpoints.
For hadoop people, by the way… this specifically uses the MR2 daemons which structured a little different than those in MR1. But essentially, the concepts are the same.
So : Heres how this is going to work.
We will debug a hadoop cluster which is running apache big tops VM.
Each step below either happens on your GUEST (the machine which is running your application, called GUEST because, in this case, we are running hadoop in a guest VM), and HOST (the machine which you have your debugger, in this case, eclipse + source code for the classes being run in GUEST jar).
Two more quick notes:
– The VM im using is running a version of hadoop which we will extract in step 2 below using the hadoop version command.
– To remotely debug a java application on a remote machine you need to have the source code for the classes running therein.
If this is confusing to you, you might want to do some basic experiments using JDP before adding the complexity of eclipse into the mix. This shouldn’t be a recipe.
In the first two steps, we will get the necessary information from our VM so that we can connect our eclipse debugger into it. By the way, of course, you don’t really need to run the app on a different machine than you have eclipse installed – you might (for example) have hadoop installed locally and eclipse running locally. In this case, just ignore the GUEST/HOST tags below, as they are irrelevant.
1) GUEST First setup your machine which will be running the java app (and make sure that your HOST machine, with eclipse on it, has network access to at least some port on the remote machine).
– You should be able to run “JPS” and see relevant processes running (MR1 : TaskTracker,/JobTracker, MR2: Resource Managers, etc…).
[root@localhost ~]# jps
6501 Jps
1630 NodeManager
1753 ResourceManager
1534 JobHistoryServer
2) GUEST Get the IP address and Hadoop version from your VM.
[root@localhost ~]# ifconfig | grep 192
inet addr:192.168.122.139 Bcast:192.168.122.255 Mask:255.255.255.0
[root@localhost ~]# hadoop version
Hadoop 2.0.5-alpha
Subversion https://git-wip-us.apache.org/repos/asf/bigtop.git -r 7242e2aede1fcabf8e2a25ea17e66f91663f682c
Compiled by jenkins on 2013-06-11T05:00Z
From source with checksum c8f4bd45ac25c31b815f311b32ef17
This command was run using /usr/lib/hadoop/hadoop-common-2.0.5-alpha.jar
Now, steps 3 and 4 below will allow you to create the source code view of the runtime in your VM. Obviously, if you ALREADY have the exact source code running in the VM, these steps are obviated.
3) GUEST Grab the relevant source code distribution from SVN or Git.
GIT
git clone https://github.com/apache/hadoop-common.git #(and then)
git checkout branch-2.0.4-alpha
SUBVERSION
svn co https://svn.apache.org/repos/asf/hadoop/common/tags/release-2.0.4-alpha/
4) HOST Build an eclipse project locally using “mvn eclipse:eclipse”.
This is specific to maven built projects : we will create the eclipse project. Confirm that it worked with “ls -l”. If your project doesn’t use maven, import the source code using some other method (i.e. standard creation of a java project in eclipse with imported source should work).
5) HOST Import the project into your workspace .

Now, your host is going to be able to add hooks into the agent which you launch the java app with in your VM… so read on… we’re almost there…!
This is where the magic starts…
6) GUEST Now, there are a few places you can attach your agent.
In hadoop-env.sh – this will debug at the client level. Edit the last lines of /usr/lib/hadoop/bin/hadoop from this
exec “$JAVA” -agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=5432 $JAVA_HEAP_MAX $HADOOP_OPTS $CLASS “$@”
To look like this:
exec “$JAVA” -agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=5432 $JAVA_HEAP_MAX $HADOOP_OPTS $CLASS “$@”
OR
In mapred-site.xml – this will debug at the task tracker level. Be careful. Because each task can be separate, you will need to launch eclipse debugger instances once for each task that runs. To debug tasks, you will add the agentlib property as a name/value pair in mapred-site.xml.
<property>
<name>mapred.child.java.opts</name>
<value>-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=5432</value>
</property>
Others?
You could find other interesting ways to add the agent hook into daemons which are running – for example, the YARN daemon. Once you understand the basics, you can use this agent in a variety of ways to, literally, debug anything.
Whats going on above?
The above statement is just adding the JVM agent hooks into the JVM process which launches your mapreduce job. That is, it is forcing the JVM at runtime to start up with the agent running. The agent will be available on port 5434 to send/receive messages from your debugger – and it will inject byte code into the runtime mapreduce processes.
 |
| This is whats going on when you remotely debug: The agent is serving as a proxy between you and your JVM app, natively injecting, intercepting, and coordinating execution of byte code per as per your debugger’s whims. |
7) GUEST Fire up a mapreduce job !
If debugging the client: You will see the “Listening for transport dt_socket at address: 5432” thingy in your client (if your debugging at the client level).
Client: You will see the logs immediately when you use the client to submit your job.
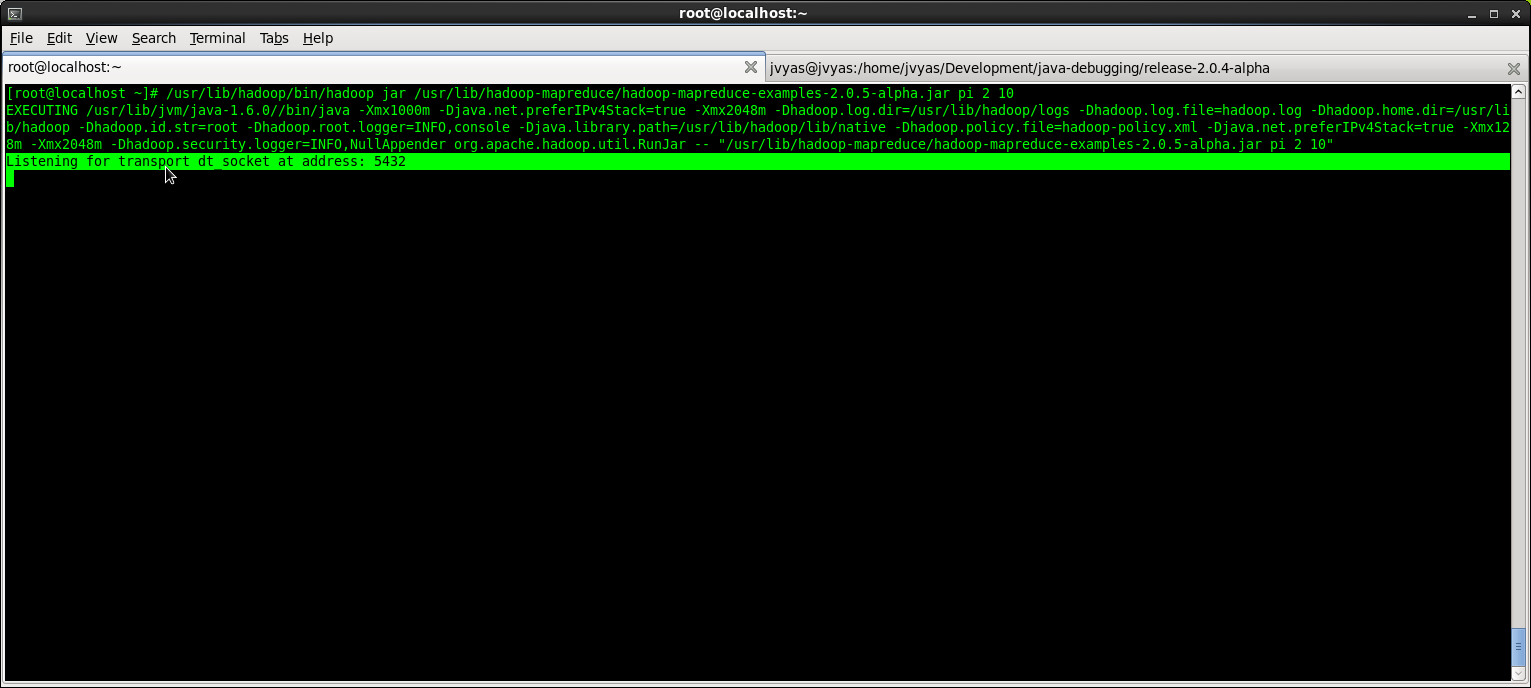
Otherwise, if debugging at the task tracker level, you can scour the node manager logs to confirm that, indeed, the child process is waiting on your debugger to proceed:
 |
| Task tracker: To see the “Listening for transport” message, you will have to dive into the node manager logs. |
Wait! Just in case you missed it… Lets look at whats going on here!!!
The agent-lib is an agent which inserts byte code into the running process. When we attach the JDWP agent, it monitors and modifies the runtime byte code so that debug hooks can be added by the host, which will get converted to byte code modifications in the guest VM (or else, whatever other JVM is running your hadoop job).
The port 5423 is what is being used for your debugger (which we will use eclipse for), to talk to the JVM agent which is hooked into the runtime for your running mapreduce job.
8) HOST Right click on the debugger options and attach to the remote port.

In my case, my Big top VM is running on IP 192.168.122.139. So, to setup the debug launch configuration, I simply put that IP in with the port 5423. At that point, the two Java apps (debugger, and debuggee) are married, and debugger (which is eclipse) can send requests to the debuggee (my VM running the hadoop PI example).
9) HOST with your terminal into your VM in clear sight, click :Debug:, and watch the VM resume your java application!
 |
| Launch the debugger once for every task that runs, in the case that your debugging a task tracker for hadoop. |
Now, you can redo steps 7,8,9 by changing break points in your runtime.
You are now a java debugging god.